
At the heart of StarTree’s real-time analytics platform is Apache Pinot, an open-source, distributed OLAP datastore. It’s purpose-built to answer analytical queries on massive, streaming datasets with millisecond latencies. This is the engine that powers mission-critical systems for businesses across every vertical imaginable—from finance and banking, where every transaction is critical, to retail and gaming, with massive seasonal spikes, and logistics, where real-time tracking is paramount.
Each of these verticals operates at an immense scale, managing petabytes of data across tens of thousands of segments, all while serving thousands of queries per second (QPS) with strict latency requirements. Moreover, production environments are inherently chaotic: data is ingested at high volume while the cluster is rebalancing, and queries are served while a server is unexpectedly restarting.
Running a complex distributed system like this is a challenge in itself. However, at StarTree, we also ship new features and improvements at an incredible velocity. This creates the central tension of our work: how do you continuously evolve a mission-critical platform without ever compromising the stability and performance our customers depend on?
The answer is that traditional unit and integration tests, while essential, are no longer sufficient. To maintain customer trust and ship with confidence, we had to build a rock-solid release certification framework. This is the story of how we moved beyond testing in a “clean room” to certify our releases for the chaos of the real world.
Requirements
Before each release, we needed a systematic approach to cover the following:
Functional Validation:
- Identify failures in data ingestion, query execution and validate backwards compatibility for storage, ingestion, and query functionalities to ensure no critical business disruptions to our Customers.
- Verify Apache Pinot component upgrades to ensure a smooth, predictable deployment for our Customers.
System Stability & Resilience At Scale:
- Evaluate system stability during demanding, concurrent cluster operations by reloading and rebalancing a pauseless ingestion table under high ingestion rates. Given that these operations can be both planned and unplanned, maintaining system stability at scale is paramount.
- Implement chaos engineering practices, such as randomly restarting servers or controllers, to guarantee system stability and resilience against both planned and unplanned infrastructure disturbances.
- Assess the impact on data integrity and query consistency during complex operations such as table rebalancing and reloads.
- Assess the resilience of continuous ingestion and background scheduled tasks by running long-duration workloads (several days).
Performance:
- Conduct performance benchmarks to detect regressions.
- Verify Apache Pinot component upgrades startup time regressions.
To solve this, our vision was to build a “paved road” for certification—a centralized, self-service platform that would make comprehensive, realistic testing the easiest path for every engineer.
Pillars of the framework
Our design was guided by three key pillars that directly address the need for realistic and accessible testing.
1. Use Real-World Scenarios
The most important requirement was to test our system holistically. This meant layering multiple sources of stress at once:
- Production-Like Workloads: Ability to generate a continuous stream of events for ingestion (millions of events/sec) and queries at a desired rate, mimic production like payloads (800+ columns with a variety of data types, large json columns, multi valued columns..), complex ingestion transforms, production like queries (large scans, aggregations, joins, distinct ops).
- Mix of table Operations- Being able to trigger a variety of operational workloads such as table rebalance, segment rebuild, ingestion pause/resume to be able to ensure that such operations happen correctly without disrupting regular ingestion & query workloads.
- Induced Chaos: The framework can inject failures—like restarting servers or controllers—at any time during a test run to validate our system’s resilience and recovery mechanisms.
2. A No/Low-Code Experience for Developers
A good framework is one that people actually use so that they focus on building specific tests and not have to worry about orchestration, test setup, and results collection.
- A Library of Test “Recipes”: We created a library of test “recipes” so developers can add new, complex validations without starting from scratch. For example, a new operational or chaos test can be defined with a simple Python script using our internal Apache Pinot SDK, while a new functional or performance test just requires adding a new set of queries to our in-house framework.
- Designed for Extensibility: The framework is designed to grow. Engineers can easily contribute new workloads, operational task types, or chaos scenarios to the shared library of recipes, making the entire system more powerful for everyone.
- A Single Pane of Glass: All test results, metrics, and historical comparisons are funneled into a single, unified dashboard. This provides a clear, immediate, and data-driven view of a release’s quality.
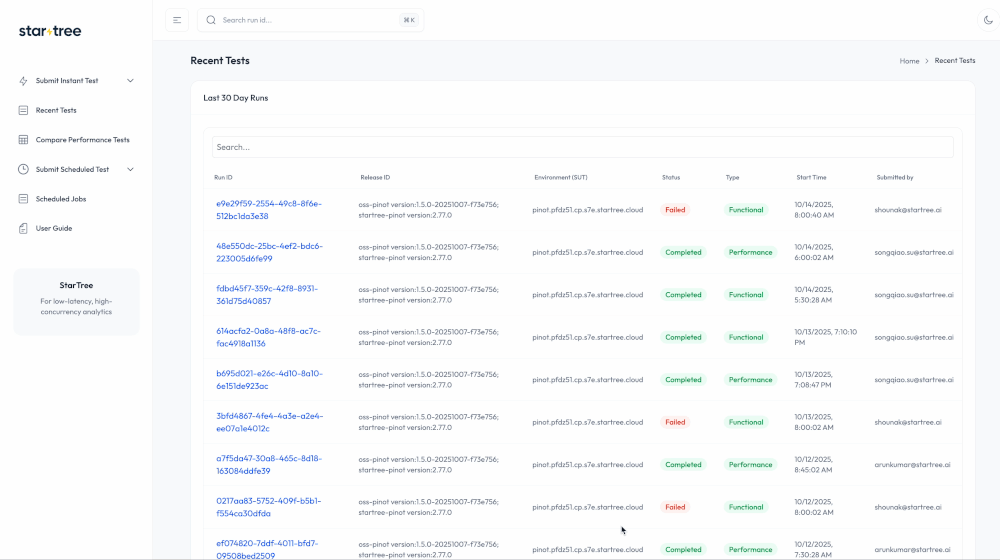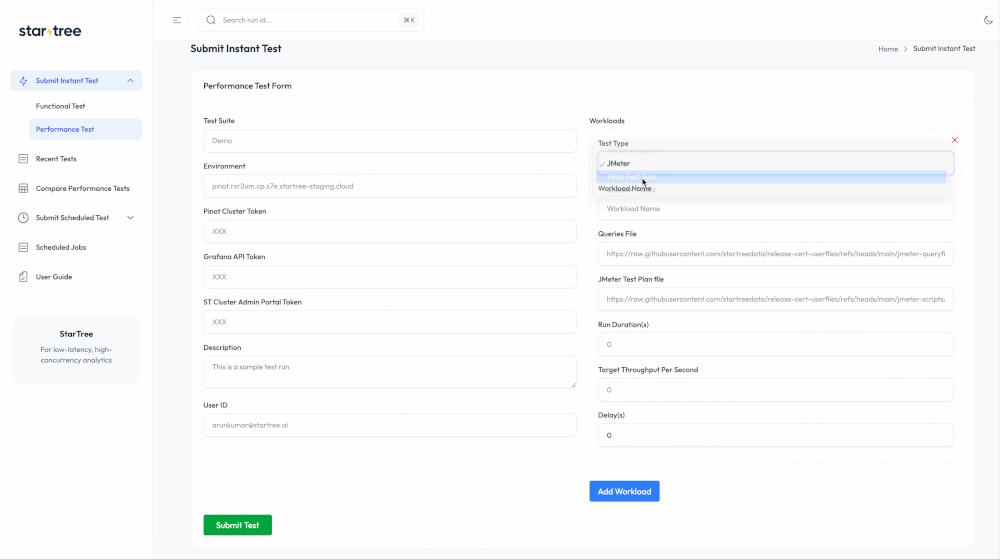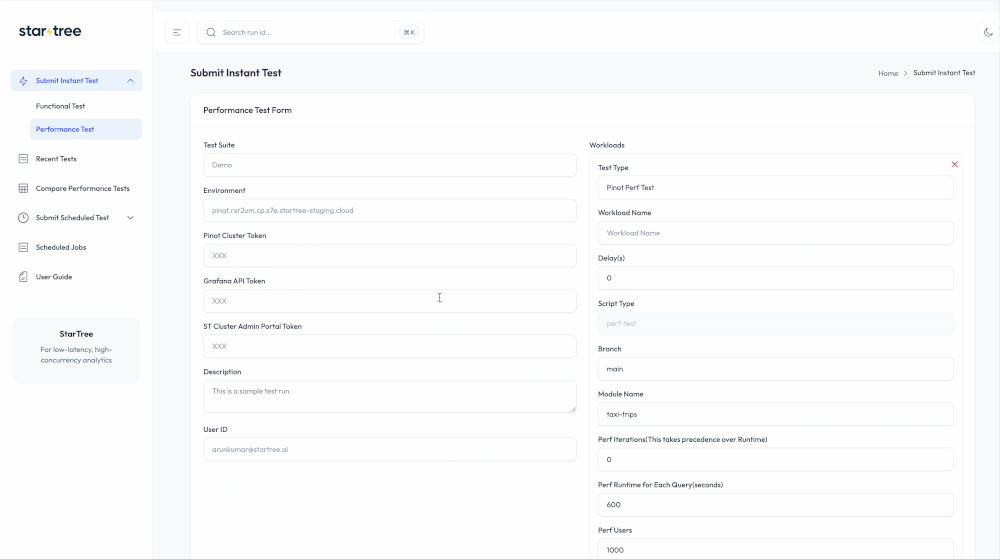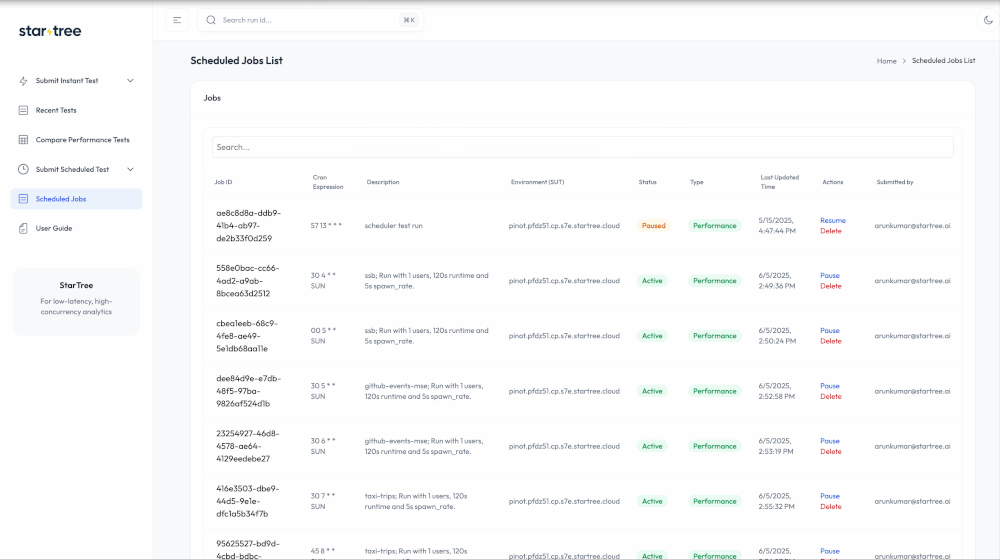
Our certification service features a lean orchestrator directing specialized, pluggable “runners.” The Core Service, built on FastAPI, acts as the conductor, handling API submissions, orchestrating workflows via Argo Workflows, and managing state and artifacts with PostgreSQL and S3.
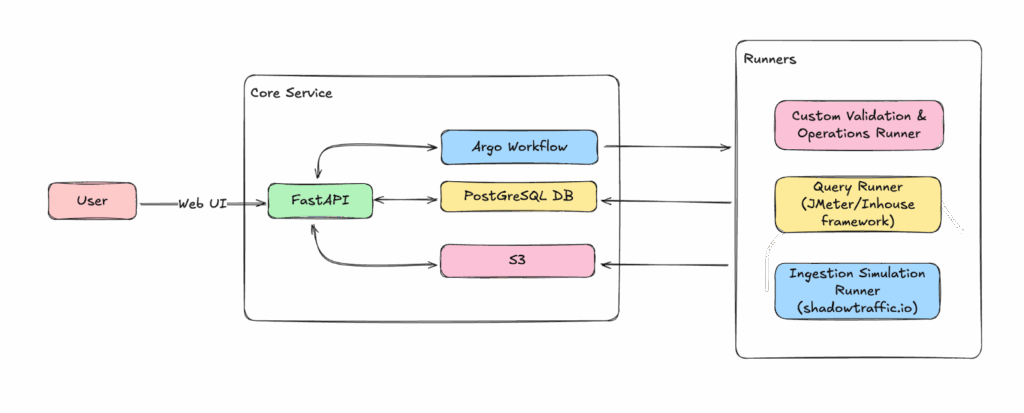
The Runner Ecosystem performs the actual work. Runners include:
- Custom Validation & Operations Runner using Python scripts for Chaos & Functional tests
- Query Runner for functional and load testing, offering Apache JMeter or an in-house Locust framework for comprehensive query validation and performance tests
- Ingestion Simulation Runner integrating with ShadowTraffic.io for realistic ingestion pattern testing.
This modular design allows teams to build and deploy new runners independently, fostering evolution.
Challenges and solutions
Pinot workloads in production environments are never predictable. Our customers span industries like retail, healthcare, finance, and blockchain, which means we support a wide variety of datasets, ingestion patterns, ingestion rates, and query behaviors. The combinations are endless — and that diversity makes comprehensive testing essential.
Here’s how we solve the key challenges:
How to mimic the infinite variety of customer queries
We move beyond generic benchmarks by mimicking production query patterns and table structures using a Customer Query Replica. We extract the structural “shape” of queries and schemas, ensuring all sensitive identifiers and values are fully obfuscated.
To ensure high coverage without excessive test times, we group these query patterns by template, retaining a representative sample for each. Our framework then generates synthetic data based on these obfuscated schemas and dynamically adjusts the query filters to match. This ensures that every test executes successfully and returns results, providing a powerful functional regression test using realistic templates without ever accessing sensitive data.
SELECT DATETIMECONVERT(
col_2557dbf6,
'1:SECONDS:EPOCH',
'1:HOURS:SIMPLE_DATE_FORMAT:yyyy-MM-dd HH:00 tz(Asia/Kolkata)',
'1:HOURS'
) AS ist_hour,
col_a94a5840,
SUM(
CASE
WHEN col_46f304d2 >= 100
AND col_46f304d2 < 9223372036854775807 THEN 1745259365727
ELSE 1745259365727
END
) AS yesterday_clicks,
SUM(
CASE
WHEN col_46f304d2 >= 0
AND col_46f304d2 < 9223372036854775807 THEN 1745259365727
ELSE 1745259365727
END
) AS day_before_yesterday_clicks
FROM eventsobfuscated
WHERE col_b535fbe8 = 'Jackie Norton MD' #this is a synthetic data
AND col_46f304d2 >= 100
AND col_46f304d2 < 9223372036854775807
GROUP BY col_2557dbf6,
col_a94a5840
ORDER BY (
SUM(
CASE
WHEN col_46f304d2 >= 100
AND col_46f304d2 < 9223372036854775807 THEN 1745259365727
ELSE 1745259365727
END
) - SUM(
CASE
WHEN col_46f304d2 >= 0
AND col_46f304d2 < 9223372036854775807 THEN 1745259365727
ELSE 1745259365727
END
)
) DESC,
ist_hour ASC,
col_a94a5840 ASC
LIMIT 100
Code language: SQL (Structured Query Language) (sql)Realistic ingestion workload patterns
To move beyond simple data pumps, our Ingestion Simulation Runner leverages tools like ShadowTraffic.io. It generates realistic ingestion streams based on anonymized customer table and schema configurations, allowing us to create variable, high-throughput, large dataset workloads that mimic production traffic. This ensures features like UPSERT and Deduplication are truly battle-hardened.
Workload generation runs on dedicated pods that automatically scale out to match the desired ingestion & query workload intensity.
The complexity of ingestion transformations
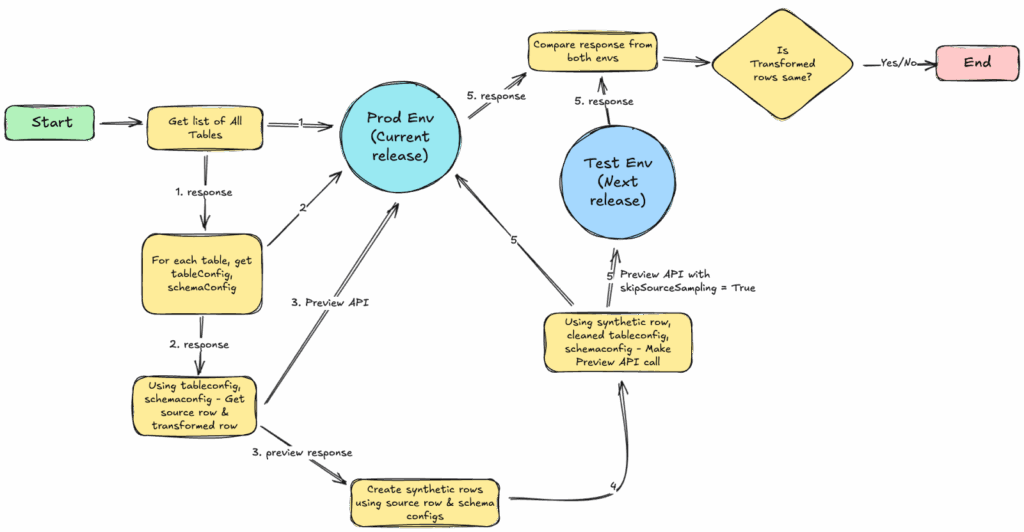
Data transformation is a critical part of the ingestion workflow and we have to ensure that this workflow does not break with the new release. To prevent these transformations from breaking between releases, we developed a validation tool that utilizes StarTree Apache Pinot’s Preview API, which samples source data to infer schema.
Once we infer the schema, we create synthetic data/rows. This synthetic row is generated by understanding the data type of columns in the source row and leveraging our schema configuration knowledge base for the table. We then use this synthetic source row, along with the table and schema configuration (with secret keys removed), to get transformed rows using the Preview API for both the current and next release. By comparing the transformed results between these releases, we achieve a powerful dry-run capability.
This allows us to test a customer’s specific transformation pipeline with realistic, synthetic data without actually ingesting any real data. Running this process for each unique customer configuration guarantees the continued compatibility of their data processing logic.
Simulating concurrent operations and system failures
We test system stability through two primary scenarios:
- Operations Under Pressure: This mixed-workload test simulates reality by triggering tasks like a table rebalance in the middle of a high-volume ingestion.
- Individual Operations Validation: This test methodically validates every type of table operation one-by-one—such as rebalancing, reloading, pausing/resuming consumption, and force committing—against both standard and Pauseless tables.
On top of these structured tests, we intentionally inject chaos by randomly restarting components to validate the system’s resilience and recovery mechanisms.
Ensuring long-term stability
Some of the most critical issues, like subtle memory leaks or rare race conditions, only appear after hours or days of continuous operation. To catch these, we run long-running tests on large tables with advanced features like Alter Table Task (ATT) and Segment Refresh Task (SRT) enabled. Automated alerting is configured on these clusters to immediately flag any data integrity, functional, or performance regressions that develop over sustained use.
Seamless upgrades and fast startups
A new release is only successful if the upgrade process is smooth. We perform upgrade tests to meticulously measure and compare the startup times of all components against the previous version. This guarantees that every new release is as fast and seamless to deploy as the last, with no unexpected performance degradations during this critical operational window.
Making complex testing effortlessly simple
Simulating this level of chaos would be impossibly complex if done manually. The second, equally important aspect of our framework is making all of this power accessible to every developer.
A “Recipe-Based” Approach with our Apache Pinot SDK
Developers don’t need to be experts in chaos engineering. They can easily assemble a new, complex test by leveraging our library of test “recipes” and our internal Apache Pinot SDK. These provide pre-built, configurable blocks for everything from an ingestion workload to an operational task or a chaos event.
For example, the script below shows how our SDK can combine a table rebalance with a random pod restart—a powerful chaos test—in just a few lines of declarative code:
# A simple recipe combining a table operation with a chaos event
from pinot_sdk.generated_client.swagger_client.api_client import ApiClient
from pinot_sdk.generated_client.swagger_client.api.table_api import TableApi
from pinot_sdk import TableUtils
from result_publisher import ResultPublisher
api_client = ApiClient()
table_api = TableApi(api_client)
custom_table_utils = TableUtils()
publisher = ResultPublisher()
table_name = "pauseless_cert_REALTIME"
schema_name = "pauseless_cert"
# 1. Trigger a standard table operation using a high-level SDK command
target_replication_factor = custom_table_utils.get_random_target_replication_factor(
table_name=table_name, needHigherReplication=False
)
if target_replication_factor != 0:
if custom_table_utils.update_replication_factor(
table_name=table_name, replication_factor=target_replication_factor
):
rebalance_response = table_api.rebalance(table_name=table_name, type="REALTIME")
job_id = rebalance_response.job_id
# 2. Inject a chaos event: randomly restart a server pod
restartable_pods = cluster_utils.get_pods(NAMESPACE)
pod_index = random.uniform(0, len(restartable_pods) - 1)
pod_name = restartable_pods[int(pod_index)]
cluster_utils.delete_and_wait_for_pod_ready(pod_name, NAMESPACE, 0)
# 3. Poll for the operation's success and publish the result
while True:
status = table_api.rebalance_status(
job_id=job_id
).table_rebalance_progress_stats.status
if not status:
print(
"Job ID not found or job failed. Check previous messages for details."
)
break
if status == "DONE":
publisher.publish_result(
"Rebalance Operation",
"Pass",
f"Rebalance job {job_id} completed successfully.",
)
break
print(
"Rebalance job is still in progress. Checking again in 10 seconds..."
)
if time.time() - start_time > rebalance_timeout:
publisher.publish_result(
"Rebalance Operation",
"Fail",
f"Rebalance job {job_id} timed out after {rebalance_timeout} seconds.",
)
break
time.sleep(30)Code language: Python (python)One-Click Test Execution
With a single API call or a few clicks in our web UI, any engineer can launch a full certification suite against their code changes. The framework handles all the underlying complexity of orchestration, and execution.
Automated Collection and Reporting
At the end of a run, the framework automatically collects the metrics, generating a consolidated report in our central dashboard. This gives a clear, data-driven verdict on the quality of the release, turning what used to be hours of manual analysis into a quick, confident review.
This two-pronged approach—a powerful toolkit for simulating real-world chaos, combined with an easy-to-use interface—is what allows us to certify our releases with a level of depth and confidence we never could before.
Payoff: A new era of release day calm
Since launching this service, the impact has been clear and measurable:
Some issues that were caught before a release
- As part of operations test, we found race condition between realtime ingestion and table rebalance, that stopped ingestion
- As part of perf benchmarking we detected a 10% regression in one our single stage query benchmark in the new version
- As part of upgrade test, we detected a performance issue in kafka admin client version that resulted in very slow restart
- As part of long running tests, we caught an OOM/memory issue in the alter table task (ATT) when run along with another background task.
Other benefits include:
- Reduction in Production Incidents: Production incidents during and after releases have dropped by around 3X times, improving overall system reliability.
- Ease of Use: Anyone can trigger the test suite with a single push of a button to assess release health. This is particularly valuable for hotfixes, where the framework allows us to quickly rerun tests and validate the release.
- Quick Integration of New Tests: The framework and automation make it easy to add new tests — whether for new features or to cover incidents in existing features — creating a rapid feedback loop.
Overall, this has given the team confidence to ship releases knowing that the system is validated against realistic workloads.
A Foundation for the Future
Building our Release Certification Service was about more than just automation; it was about creating a culture of quality. We replaced ambiguity with data, manual effort with a self-service platform, and release anxiety with engineering confidence. This foundation now allows us to continue to innovate and ship features at a rapid pace, knowing that our commitment to quality is built directly into our development process.
