
Over the past several years, Apache Iceberg has earned its place as the open standard for modern data platforms. It fixed problems every serious data team has wrestled with: unreliable tables on object storage, brittle schema evolution, opaque governance models, and vendor lock-in. Iceberg brought ACID guarantees to the lake, made schema changes survivable, and created a shared system of record that supports multiple engines.
If you’ve invested in Iceberg, you’ve likely felt that consolidation benefit. Data written once. Governed once. Queryable by many engines. Fewer copies. Fewer pipelines. Fewer political battles between teams.
That’s real progress.
But if we’re honest, most teams initially treat Iceberg as a better data lake. A forklift upgrade. A lift-and-shift from one table format to another.
Valuable? Absolutely. Transformational? Not yet.
Because most Iceberg architectures are still designed around two familiar workload categories.
Two data-lake workloads everyone understands
When enterprises adopt Apache Iceberg, they almost always design around two primary categories of work. These categories are well understood, and they map cleanly to the lakehouse architecture.
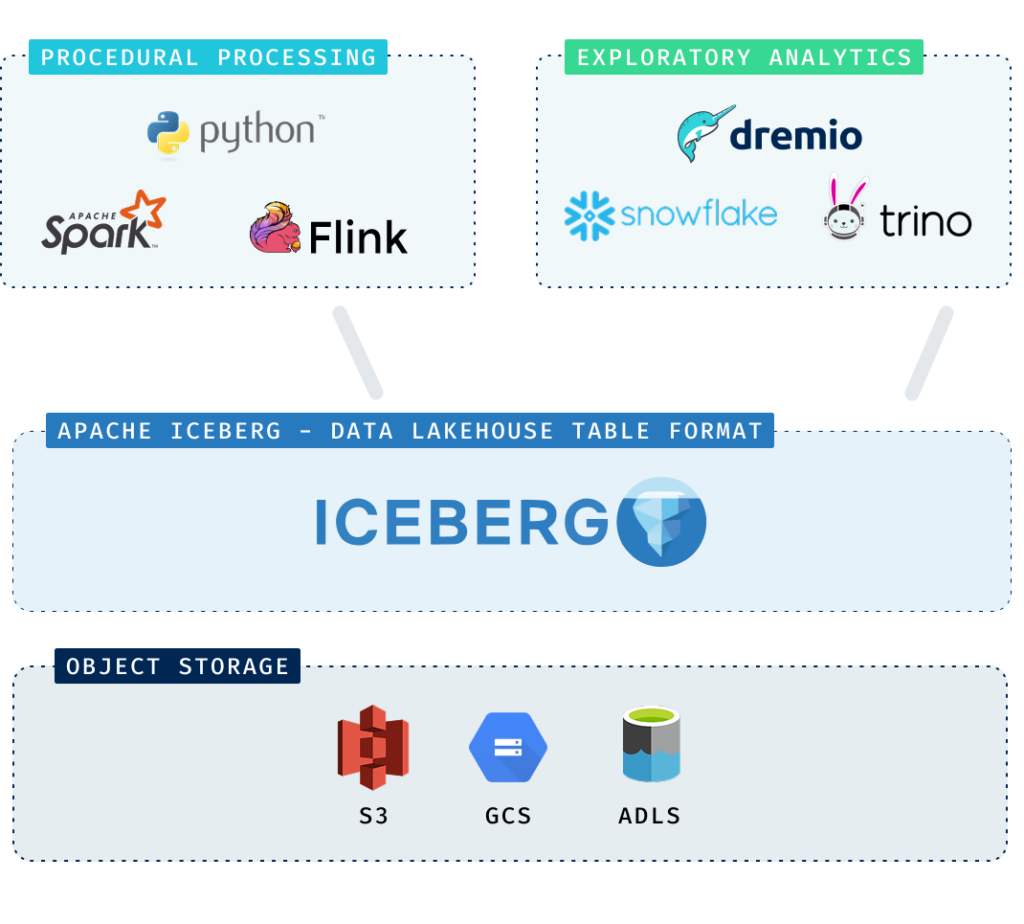
The first is exploratory analytics. This is the domain of analysts, BI teams, and power-users asking questions of the business. It includes executive and operational dashboards, ad hoc analysis of product usage and customer behavior, and deep dives into trends or anomalies. These workloads prioritize analytical flexibility and broad tool compatibility—strong SQL support, Postgres wire protocol compliance, seamless BI integration. Engines such as Trino, Databricks SQL, and Snowflake are commonly used here. Query times may vary depending on scope and data volume, and that variability is acceptable. In exploratory analysis. Iceberg was designed to support this kind of flexible, multi-engine access to governed data.
The second category is procedural processing. This is the domain of data engineering and machine learning teams. It includes enrichment and transformation pipelines, feature engineering, model training and retraining cycles, and large-scale prediction jobs that write results back to Iceberg. These workloads are typically executed in frameworks such as Apache Spark, Apache Flink, or Python-based processing systems. Here, the priorities are reliability, scalability, and throughput. The objective is to move data efficiently from one stage of the lifecycle to the next.
Both categories align cleanly with Iceberg’s strengths as a durable, governed system of record. And because they are so common—and so well supported—they are the workloads most architectures are intentionally built to handle.
SLA-driven analytics on the data lake – the workload most people don’t think is possible
There is a category of analytics that behaves differently from the rest. These are not exploratory dashboards or internal ad hoc queries. They carry guarantees—explicit or implicit service level agreements. Broadly, they fall into two classes: customer-facing data products and mission-critical operational analytics.
Customer-facing data products are the metrics embedded directly into your application experience. These power usage dashboards inside your product, fintech merchant cash flow views, surge pricing systems adjusting supply and demand curves, or logistics portals where customers log in to see shipping performance by class of service and route. In these cases, analytics is the product. Latency, freshness, and consistency shape user trust and retention. If a dashboard spins, numbers lag reality, or filters behave unpredictably under load, the customer experiences it as product instability.
Mission-critical operational analytics are the systems the business relies on to function in real time. These include incident response investigation tools used by SRE teams during outages, real-time ad campaign pacing and funnel analytics, and fraud detection workflows evaluating transactions as they occur. These workloads are often exercised hardest during moments of peak stress—traffic spikes, attacks, or service degradations—when predictable performance matters most.
Both classes share a defining requirement: deterministic behavior. It’s not enough for the average query to be fast. P95 and P99 latency, data freshness guarantees, and sustained throughput under load become architectural constraints.
We call this class of workloads SLA-Driven Analytics.
If You Don’t Design for Determinism, Someone Else Will
Most shared data layers on Apache Iceberg are optimized for the right reasons: storage efficiency, clean schema management, analytical flexibility, and high-throughput batch workloads. For exploration, reporting, and offline analytics, this architecture performs well. On average, queries are fast enough. Costs are predictable. The system feels stable.
But SLA-driven analytics are not judged on averages.
When deterministic latency and freshness guarantees are required, but the underlying architecture wasn’t designed to provide them, teams compensate. Not because they enjoy complexity, but because the business demands certainty. They preprocess and pre-aggregate data. They replicate subsets into specialized stores. They add caching tiers. They isolate workloads to prevent noisy neighbors from disrupting tail latency.
Gradually, something subtle happens. The “shared system of record” remains central for storage and governance, but the workloads most directly tied to revenue and customer experience begin executing elsewhere. The lake becomes a feeder system rather than the execution layer.
Data moves more often. Pipelines multiply. Compute footprints expand to smooth over P95 and P99 spikes. Monitoring grows more elaborate to defend SLAs. Engineering effort shifts toward maintaining consistency across replicated tiers. During peak operational moments—when traffic surges or incidents unfold—the architecture shows its seams.
None of this feels catastrophic. It feels incremental. Justifiable. Necessary.
But over time, the hidden cost of “good enough” becomes architectural drag: more systems to operate, more data copies to reconcile, and more infrastructure to sustain guarantees that were never native to the design.
SLA-driven analytics sit uncomfortably close to the business. They shape customer experience, influence revenue workflows, and guide operational decision-making. When they degrade, it’s highly visible.
If they aren’t designed intentionally, organizations tend to drift toward one of two bad outcomes.
The first is a loss of trust.
When customer-facing dashboards stall or incident response queries slow or logs arrive stale, they ask why the data platform couldn’t deliver.
You may understand the architectural root cause of systems stretched into SLA driven roles. But perception hardens quickly. If SLA-bound workloads behave unpredictably, confidence in the platform’s reliability erodes. And once stakeholders begin routing around you for certainty, trust becomes difficult to rebuild.
The second outcome is leadership abdication.
When SLA-driven analytics are treated as someone else’s problem, they don’t disappear. They reappear as shadow architectures.
Product teams introduce separate serving layers. Engineering embeds logic directly into applications. Caches and replicas multiply. Each decision is rational; teams have deadlines and revenue commitments. They need guarantees.
But collectively, those decisions redefine your role. The data platform stops being the authoritative layer for mission-critical analytics. It becomes an upstream data provider feeding systems you don’t control. Instead of setting architectural direction, you’re accommodating it.
That’s the difference between “good enough” and deterministic SLAs in Iceberg: diminished trust and authority.
A query engine for SLA-driven analytics on Iceberg?
One of Iceberg’s most important design decisions is the clean separation of storage and compute. A single table format can support multiple, fit-for-purpose execution engines, each optimized for a different class of workload. Procedural engines use it for transformation, enrichment, and modeling. Exploratory SQL engines operate directly on it for BI, ad hoc analysis, and deep investigation. Each engine plays to its strengths without compromising the integrity of the data layer.
The missing piece is an engine designed to solve for SLA-driven analytics. An engine that treats it not as an afterthought, but as a first-class workload category.
That is what StarTree Cloud offers.
Building on the impressive real-time query capabilities of Apache Pinot, StarTree Cloud is able to query data in Iceberg tables with deterministic guarantees: guarantees on freshness; guarantees on tail latency; and guarantees that hold even as data volumes grow and query concurrency spikes.
On StarTree Cloud, you can serve high-performance queries on data that remains in Iceberg. No need to move data to a specialized system for serving. Governance remains centralized.
Now, with your data stored in a shared foundation, and a selection of query engines optimized for different workloads, you can process, analyze AND serve from a single source of truth.

How StarTree implements the SLA layer
StarTree approaches Iceberg with a clear architectural principle: minimize remote I/O.
Iceberg stores data in Parquet files on object storage. The dominant cost for any query engine is network fetch latency, not CPU. A fast, scalable engine must be designed to read less data. StarTree achieves this by stacking multiple engineering optimizations:
Metadata-based pruning
Pinot uses Iceberg partition metadata and column statistics to eliminate entire segments before any remote read occurs. This prevents unnecessary object store calls and shrinks the working set early in the query lifecycle.
Bloom filters further enable Pinot to prune segments that are not relevant to the query. These optimizations all happen before Pinot needs to scan any data.
Powerful indexes
Pinot is known for it’s varied indexing capabilities. These map predicates directly to document IDs and specific Parquet pages. Instead of scanning full files or even entire column chunks, Pinot identifies the minimal set of pages required to satisfy a query. Pinot supports inverted, range, JSON, geospatial (H3), Star-Tree, forward, text (Lucene), vector, bloom filter, timestamp, and sparse indexes. Many general-purpose engines operate at coarser fetch granularity, which increases I/O even for highly selective filters.
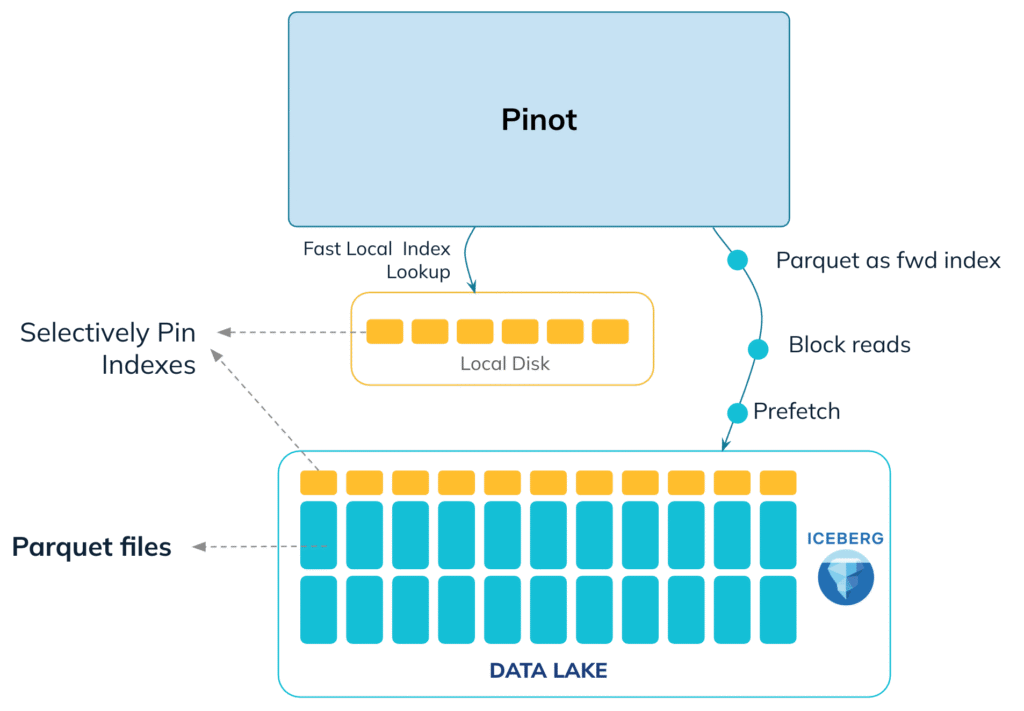
Execution is structured to hide latency
During query planning, Pinot servers begin prefetching required Parquet pages and decompress them in parallel across threads. By overlapping fetch and execution phases, the system minimizes I/O stalls. A custom Parquet reader integrates tightly with Pinot’s indexing and caching layers, avoiding the abstraction overhead common in generic readers.
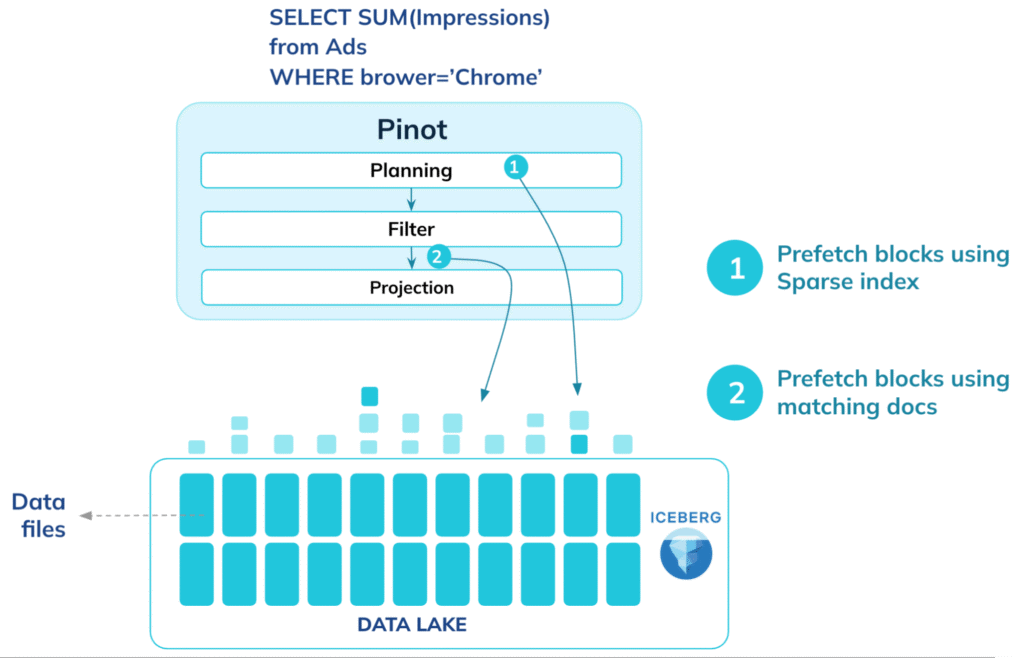
Hierarchical caching
By separating data and index caches, frequently accessed metadata, index structures, and data pages can remain close to the CPU. This sustains high concurrency while keeping object-store traffic bounded.
Iceberg remains the system of record, while Pinot provides deterministic querying for SLA-driven analytics.
Learn more about how Apache Pinot on StarTree Cloud has evolved into a highly efficient query engine for Iceberg
So, how many QPS can Iceberg support?
Benchmarking validates that with the right architectural optimizations—metadata pruning, intelligent indexing, prefetching, custom Parquet reader, and hierarchical caching—StarTree Cloud can deliver sub-second query latency and high throughput directly on Iceberg. Results are comparable to querying locally ingested Pinot tables. When caching is enabled, query latency and throughput effectively match Pinot local performance while operating at a fraction of the cost, since data stays in Iceberg with no duplication or ETL overhead.
This fundamentally changes the economics of real-time analytics. Organizations can now serve low-latency, high-concurrency workloads directly from their Iceberg data lake, using Pinot as a lightweight, query acceleration layer. Whether for personalized recommendations, operational dashboards, or campaign analytics, this approach combines the flexibility of open data formats with the performance of a purpose-built serving engine—bringing true “always-on analytics” to the modern data stack.
500 Queries per Second with Apache Pinot and Iceberg
Experience SLA-driven analytics on Iceberg with StarTree Cloud
The best way to experience what is possible with SLA-driven analytics on the data lake, is with a quick demo from the Pinot experts at StarTree. And, if you see potential, we’ll set you up with a trial account to prove it out with your own data.