
Elasticsearch originated as a search engine. Its strength lies in indexing and retrieving full-text documents, making it incredibly powerful for use cases like product search, log search, and website indexing. Apache Pinot, on the other hand is designed for real-time analytics. It was architected to answer complex, high-speed aggregation queries across massive datasets with consistently low latency.
So how did these two very different systems both end up making the short list as a viable solution for this workload? The answer lies in how modern organizations are trying to extract more value from their logs.
Traditionally, logs were searched—when did this error happen? What user triggered this exception? Elasticsearch was perfect for that. But the nature of questions has evolved. Today, teams want to analyze logs—spot patterns, aggregate across time windows, slice across multiple dimensions like region, app version, or device type, and do it all in real time.
If your goal is to search logs, Elasticsearch remains a solid choice. But if your goal is to analyze them—especially at scale—Apache Pinot is likely the better tool for the job.
In the sections that follow, we’ll walk through why, looking at:
- What it takes to get from unstructured logs to structured analytics
- How Pinot’s architecture supports real-time performance and up-to-date insights
- Why companies like Uber, Cisco, and Uniqode rely on Pinot for these use cases
Columnar vs Document Architecture for Log Analytics
Logs are messy. They often start as text files, semi-structured JSON, or key-value pairs. But logs contain valuable structure. Each entry typically includes elements like:
- Timestamps
- IP addresses
- Status codes
- User identifiers
- Error messages
- Request parameters
While Elasticsearch treats these as parts of a single document to be searched through, Pinot treats each as a distinct column to be analyzed. This fundamental difference changes everything about how logs can be processed and queried.
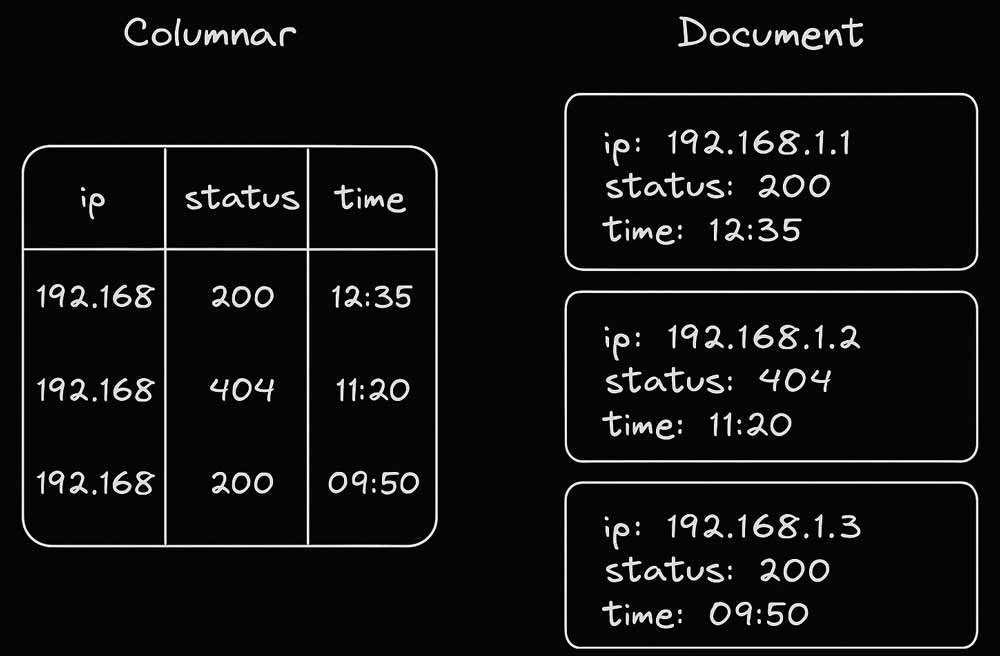
Column StorageSlash Compute Costs:Only relevant columns loaded for analytics. Reduce Storage Costs: 5-10x better compression ratios due to dictionary encoding. | Document StorageExcessive compute costs: Full document scan required for analytics.Bloated storage costs: Row-oriented design has poor compression, duplicating repeated |
When log data is stored in columns rather than documents, two critical advantages emerge:
- Dramatic compression and reduced storage requirements Similar values in each column compress efficiently, reducing storage needs by 60-80% compared to document-based storage.
- Faster analytics performance Queries can access only the specific columns they need instead of scanning entire documents, enabling aggregate queries that are 5-150x faster than in Elasticsearch.
Most analytical use cases benefit greatly from structure—you don’t just want to search for a string, you want to analyze patterns, distributions, time windows and anomalies. When logs are decomposed into structured columns: Timestamp, error code, etc., each column can be individually indexed and optimized for fast, concurrent queries.
That leads us to one of Pinot’s superpowers: Flexible indexing.
Indexing for Analytics vs Search
When it comes to analyzing logs, Elastic and Apache Pinot take fundamentally different approaches to indexing that reflect their design priorities.
Elasticsearch was built for text search, not analytics. It uses inverted indexes optimized for keyword and full-text matching, which excel at finding documents that contain specific terms but perform poorly for aggregations, time-series analysis, or high-cardinality metrics. Because it’s row-oriented, each log entry is stored as a separate document, not only inflating storage but also slowing down group-bys and aggregations.
Apache Pinot, by contrast, was designed as a columnar OLAP engine optimized for analytical queries. It employs forward indexes, sorted indexes, and specialized data structures such as star-trees, range indexes, and Bloom filters to accelerate scans, aggregations, and time-based filters over massive datasets. The result is much faster query performance on metrics and trends with far lower storage overhead. The trade-off: Pinot isn’t ideal for free-form text search or fuzzy matching — it’s a purpose-built engine for sub-second analytics on structured and semi-structured log data, not a search engine for raw log retrieval.
One of the key advantages of using Pinot for log analytics is its ability to apply indexes based on each column’s data type, optimizing for fast, concurrent queries.
- Inverted index: For filtering on categorical fields
- Range index: For efficient numerical filtering and rollups
- Sorted index: For faster group-bys and top-K queries
- H3 Geo index: For location-based queries
- JSON index: For semi-structured log content
- Text index: For regex and partial matches
- Star-tree index: Pinot’s unique optimization that pre-aggregates common query patterns, reducing scan costs by over 90%.
You can mix and match these indexes per column, depending on what kind of queries you’re running. This is a massive performance advantage if you’re analyzing logs, not just searching them.
This selective, purpose-built indexing approach in Pinot provides higher performance and flexibility for analytical workloads—especially at scale.
Cold Storage of logs without the slowdown
As log data volumes grow, so do storage costs—especially when historical data needs to remain queryable. Most systems force a tradeoff: Either pay a premium for high-performance storage or accept painfully slow queries on cheaper, colder tiers. This is especially true for Elasticsearch, where accessing older data often means rehydrating entire segments just to answer a single question.
But Pinot, via StarTree Cloud, takes a smarter approach. Its precise fetching feature not only maintains fast query performance over cloud object storage data (S3 / GCS / Azure Blob Storage)—it also significantly reduces infrastructure costs by avoiding unnecessary data scans and movement. Here’s how:
- Scan only what you need fetch specific columns, not entire rows, slashing I/O and speeding up performance.
- Target the right blocks block-level reads only target the data that matches your query, eliminating unnecessary overhead.
- Pipeline execution begins fetching data during query planning, pipelining I/O and execution in parallel. This overlap slashes query latency—often by 5x or more.
- Smarter query paths with index pinning and pruning, skip irrelevant segments entirely using metadata like min/max values and bloom filters. It keeps critical index structures hot and focuses only on the most relevant data blocks.
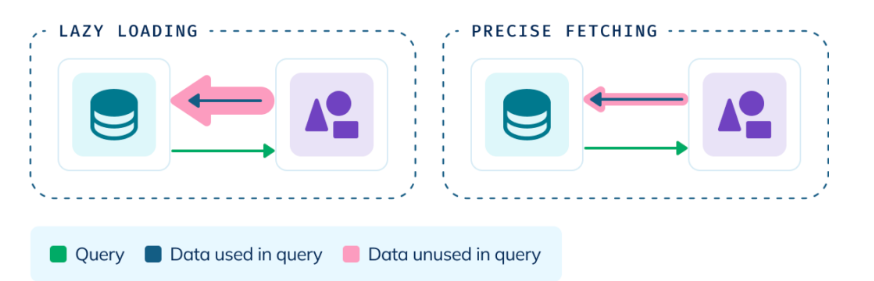
Precise fetching in StarTree’s tiered storage lets organizations economically store massive log datasets while maintaining interactive query performance—regardless of data age or storage tier. For observability teams, this means they can access and analyze months or years of historical logs with sub-second latency, enabling more powerful pattern matching over longer time horizons. The result: Faster root cause analysis, improved anomaly detection, and fewer blind spots in system health.
Discover issues immediately: data freshness at scale
Because Pinot is built to ingest from streams like Kafka and make data available for querying within seconds, you can act on what just happened—not what happened an hour ago. This is especially important in logs where fast anomaly detection is essential: Mobile crash monitoring, security incident response, system observability.
Pinot doesn’t just keep up with the stream. It handles scale. More than 10 million events per second from Kafka, without throwing hardware at the problem.
In contrast, Elasticsearch clusters tend to balloon as data grows. This increases cost and complexity. Query performance degrades and tuning becomes a never-ending project.
Since migrating from Elasticsearch to StarTree, system reliability has dramatically improved with far fewer alerts, scalability bottlenecks have been resolved, and we’ve reduced infrastructure costs by 70%—saving over $2M annually—while cutting CPU cores by 80%.
Uber Healthline
90% Reduction in Infrastructure, 10X Faster Queries: Uber Healthline
Uber’s Healthline system ingests more than 1,500 mobile crash reports per second and classifies them into buckets called issues. That’s 36TB of log data per day, retained for 45 days. These logs need to be:
- Parsed
- Compressed
- Flattened
- Sampled
- Queried with low latency
The queries range from filtering by region, app version, and time range, to generating histograms and dashboards for release managers.
Elasticsearch couldn’t keep up. Queries would time out. Clusters grew unmanageable. Once the team migrated to Pinot, they saw:
- 10x faster queries
- 90% reduction in infrastructure (7x less memory, 10x fewer cores)
- Sub-second latencies across large time ranges
- Zero query timeouts, even at peak
Pinot gave them the speed and insight they needed to confidently roll out app updates and catch regressions in near real-time.
Summary
While Elasticsearch remains an excellent choice for search-oriented applications, organizations analyzing logs for patterns, trends, and metrics consistently find better performance, lower costs, and reduced operational complexity with Apache Pinot.
- Storage Efficiency Pinot typically reduces log storage requirements by 5-10x compared to Elasticsearch through better compression of similar values
- Query Performance Analytics queries only need to access and process relevant columns, resulting in 5-150x faster query performance compared to Elasticsearch’s full document scanning
- Scalability Companies like Cisco Webex and Uber have reduced their cluster sizes by 80-90% when switching from Elasticsearch to Apache Pinot for log analytics.
- Cost Savings The combined benefits of reduced storage needs and smaller cluster sizes translate to significant infrastructure cost savings
You don’t need to choose one or the other. Many organizations use both—Elasticsearch for searching logs, Pinot for analyzing logs.
Next steps: Explore Apache Pinot for Log Analytics
The quickest way to experience the power of Apache Pinot for log analytics is with StarTree Cloud. Book a Demo or Request a Trial to get started with a no-commitment trial account to explore and test. When you’re ready to move into production, you can move into one of our cost-effective packages just right for your business.