
Customer experiences are increasingly powered by real-time insights derived from analyzing live transactions — like up-to-date profile view counts in LinkedIn, dynamic delivery time estimates in Uber Eats, and cash-flow analysis in Stripe. These aren’t internal dashboards; they’re data products served directly to millions of customers, with expectations of subsecond speed and always-fresh results.
But traditional architectures weren’t built for this. Analytical databases can’t support high concurrency, while transactional systems choke on analytical queries. To bridge the gap, teams often stitch together multiple systems — streaming, OLAP, caches — resulting in brittle, costly pipelines. Apache Pinot™ was designed to solve this problem from the ground up: a real-time OLAP database built to both analyze and serve data from streaming sources, at scale, with low latency and minimal cost.
Legacy Real-Time Analytics Stack
In the very beginning, users tried to serve analytical queries directly from their OLTP databases
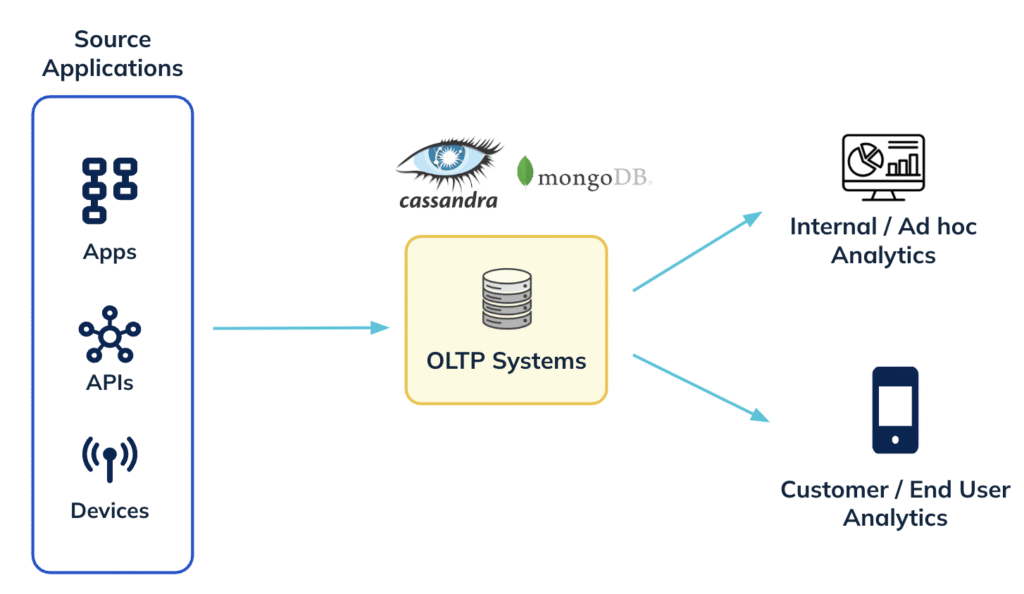
Although simple, this was clearly a bad design for various reasons. These OLTP databases were not built for running complex analytical queries. In addition, this did not provide any isolation – analytical queries would often interfere with the transactional workloads and introduce system outages. Some users tried to solve this using a read-replica based approach which solved the isolation problem however, was still not scalable or performant.
The next iteration to building real-time analytics often involved piecing together multiple complex systems as shown below:
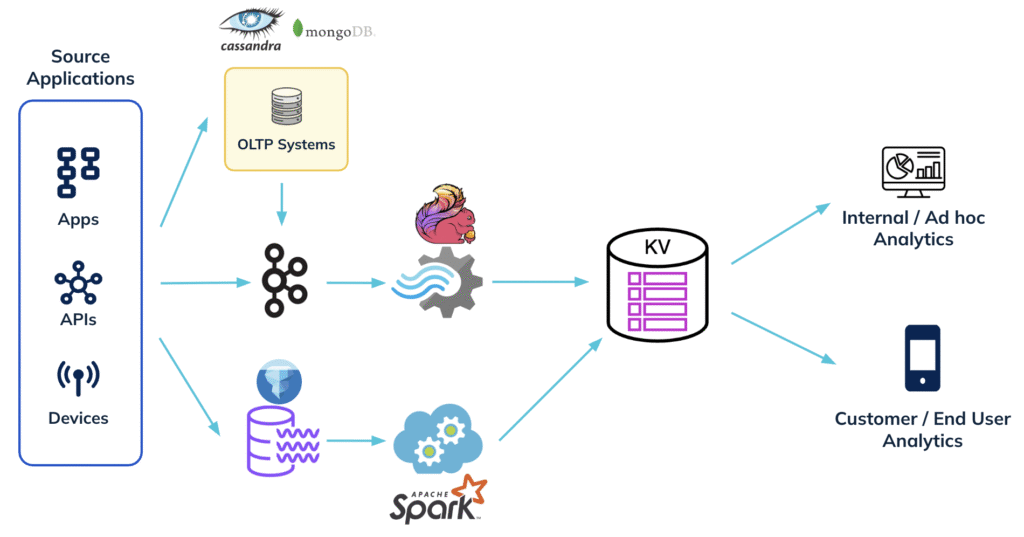
Data from real-time sources such as Apache Kafka for capturing clickstream events or OLTP databases (like MongoDB or Cassandra) for capturing entity/transaction data is used for generating pre-aggregated insights. This is done through some sort of compute framework (eg: Apache Flink). These pre-aggregated insights are typically stored in a key-value store which in turn power the live dashboards or user facing embedded insights in the app.

In most cases, data needs to be routinely backfilled or bootstrapped from a batch source like a data lake (eg: Iceberg on S3). Similar pre-aggregation is applied on this data to generate the desired insights, which are again stored in the key-value store.
While this architecture may deliver low-latency results, it comes at a steep cost—both operationally and financially.
The Pain Points: Why the Legacy Stack is Breaking
1. Data Bloat & Write Amplification
Pre-aggregated insights leads to significant data bloat since we need to compute a value for several permutations of the same dimensions. For instance, in order to generate unique user counts for every 5 minutes, we will need to store one value for each combination of
- Geography (country, region, city)
- Device (iOS, Android, Web)
- User segment (free vs. paid, age group, cohort)
- Channel (organic, referral, paid ad)
Although this simplifies the queries, ingestion overhead is significant.
2. Operational Complexity
In addition to having to maintain all the data source and applications, engineering teams now need to deploy and maintain additional components. In the example above, this refers to a real time preprocessing framework like Apache Flink, batch preprocessing framework like Apache Spark as well as a key-value store like Cassandra/Redis/Riak. In addition, this needs constant capacity planning and resharding of data to keep up with the organic growth.
3. Real-time and batch unification complexity
The exact pre-processing logic needs to be applied to both the realtime and batch ETL pipelines without which query results will be inaccurate. Needless to say this is extremely challenging to get right.
4. Inflexible Schema & Metric Evolution
Any change to schema, business logic or metric definitions requires end-to-end coordination, reprocessing, and schema synchronization across tools. This is one of the hardest problems to deal with in data engineering. In most cases, this will involve downtime for the query system.
5. Cost
Running and scaling all these layers independently inflates infrastructure costs—especially as data volumes grow.
How Apache Pinot and StarTree Cloud Simplifies Real-Time Analytics
StarTree Cloud reimagines the stack by collapsing the layers and serving fresh, on-demand analytics directly on raw data:
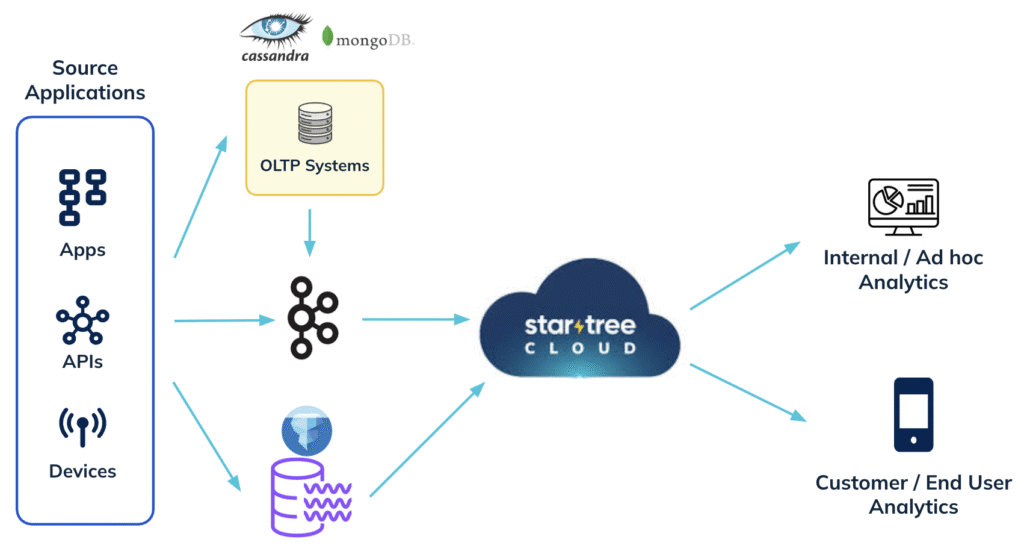
Serve Results Without Pre-Aggregation
No need to build OLAP cubes or materialize expensive pre-aggregations. Apache Pinot delivers high concurrency with low-latency queries by combining a columnar storage format with rich indexing (inverted, sorted, star-tree, json, geo-spatial). Its distributed query engine is designed to minimize data scans by using pruning techniques at various stages of query execution. This enables the platform to serve complex analytical queries on the fly with sub-second latency—even for high cardinality filters and joins. This is extremely beneficial since it avoids the expensive data bloat and hence needs a lower data footprint.
Fewer Moving Parts = Lower Cost
By eliminating intermediate layers like stream, batch processors and key-value stores, StarTree Cloud dramatically reduces operational overhead and infrastructure spend.
Easy Evolution and Maintenance – with 0 downtime
Evolving schemas, adding new dimensions, or changing metrics is much simpler when your analytics stack is not tightly coupled to pre-defined transformations and indexes. You can make these changes on the fly on live tables without any downtime !
All of this relies on the powerful performance of Apache Pinot to be able to run complex high cardinality queries on multi-dimensional data in sub-seconds. Pinot was designed to support high concurrency queries required for such serving use cases. To read more about the design choices that led to this unique serving performance, please read – What makes Apache Pinot fast ?
Real world examples
How Stripe migrated their legacy time series aggregation system to Pinot
The team at Stripe had originally built a time-series aggregation system that aggregates real-time and offline data for dozens of merchant-facing dashboard charts. This was done using a series of different systems that experience data bloat (due to over aggregation) and was complex to manage and scale. They were able to simplify this stack drastically by migrating to Apache Pinot. Key benefits of this migration include
- Support for exactly once semantics with Pinot (not possible in the previous system)
- Highly scalable and performant
- Simplified the stack – less moving parts
- Easy to maintain and scale with organic growth.
With Pinot, the time-series aggregation system now ingests millions of events per second with sub-second 20,000 QPS at 99.99% availability. All SLCs are being met, and some SLCs are even performing better compared to their previous setup. The following table highlights the spectrum of low latency queries served by Pinot @ Stripe.
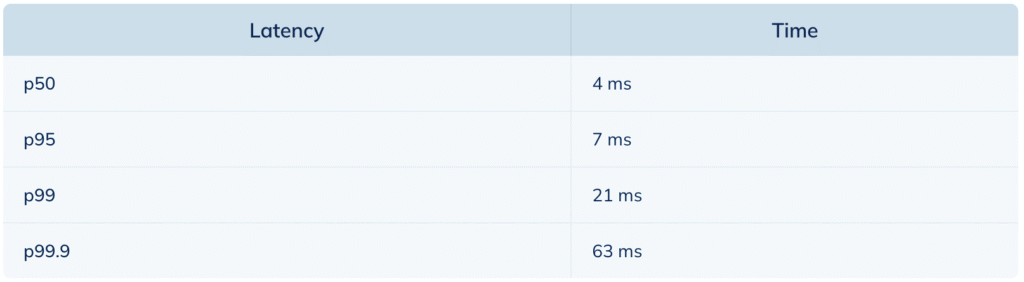
Read the full article here: https://startree.ai/user-stories/stripe-journey-to-18-b-of-transactions-with-apache-pinot
How UberEats team simplified their analytics stack using Apache Pinot
The UberEats engineering team initially used Cassandra to serve geo-spatial insights pertaining to orders in a near real time scenario. The goal was to identify popular orders happening in your area at that moment in time. This included identifying the current active orders and then filtering them based on a geofence.
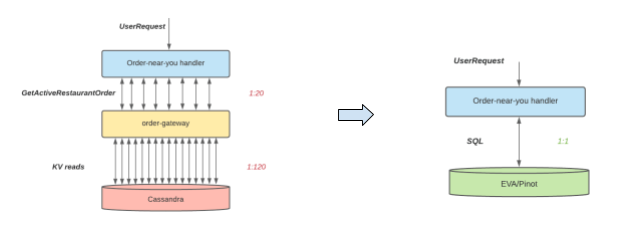
As shown in the diagram above, this solution led to a lot of queries against Cassandra and was not scalable. This was then replaced with Apache Pinot to build a much more robust and scalable solution. Here are the key benefits of this new solution
- Better engineering productivity: Developers can now describe their data retrieval logic in an SQL query, and save the efforts on developing/testing/optimizing the well-defined operations like aggregation/sort/filtering. In this case, The Eats team was able to go from design to full launch within a couple weeks for the new design.
- Better query latency: New architecture on Pinot demonstrated much better query latency (<50ms) than the previous one (several seconds.).
- Better cost efficiency: The decoupling of online OLTP from real-time OLAP opens the opportunity for scaling the storage use efficiently for different purposes. In the previous design, the Cassandra cluster would have to expand six times to handle the new heavy analytical read traffic, even though the operational writes do not change. In contrast, the real-time OLAP engine in the new architecture can easily expand or shrink, depending on analytical traffic needs. In fact, the footprint of the Pinot servers for this use case is quite small, with less than a dozen hosts.
Read the full article here: https://www.uber.com/blog/orders-near-you/
The StarTree Cloud Advantage
With StarTree cloud you get all the benefits of Apache Pinot in a fully managed, cloud native environment. In addition, Startree Cloud also boasts the following unique features that further simplifies the analytics stack for users:
Cloud Tiered Storage
Store historical data in low-cost cloud object storage, while still making it queryable via StarTree’s tiered storage architecture. This helps maintain performance for recent data while reducing cost for older datasets.
Iceberg-Native Querying
Have data in Apache Iceberg? StarTree Cloud can directly query Iceberg tables without ingesting them. You get powerful secondary indexes on top of your lakehouse data—no duplication, no data movement.
Summary
| Challenge | Traditional Stack | StarTree Cloud |
|---|---|---|
| Cost | High (multiple systems) | Lower (converged architecture) |
| Data Duplication | Yes | No |
| Operational Overhead | High | Low |
| Real-time + Historical | Complex | Seamless |
| Schema Evolution | Painful | Simple |
| Time to Value | Weeks/Months | Hours/Days |
Conclusion
If your team is spending more time maintaining infrastructure than extracting insights from data, it’s time to rethink your real-time analytics stack.
StarTree Cloud brings the performance, flexibility, and simplicity that modern companies need to stay competitive—without the baggage of legacy architectures. Whether you’re powering user-facing dashboards or building the next generation of AI-driven products, StarTree helps you do it faster, cheaper, and with far less complexity.
Want to see StarTree Cloud in action? Book a demo and discover how to future-proof your real-time analytics stack.
