

This blog covers the evolution of analytics from batch for internal use, to low-latency serving, the rise of Iceberg, and how Apache Pinot now delivers first-class support for serving directly on the data lake.
Background
When you think of analytics, there are two very different categories of systems today, each built for a reason.
Data warehouses are the traditional big databases. They collect data from all the smaller databases within an organization, using ETL pipelines extracting data, transforming it into a structured format, and loading it into the warehouse. These pipelines are typically batch-oriented, running overnight or on a scheduled cadence, powering ad-hoc analytics, internal dashboards, and historical reporting. BigQuery, Snowflake, and Teradata are some of the familiar players in this space.
For a long time, this model worked well. But then came the data explosion, first fueled by event-driven architectures, and now supercharged by the AI wave. Every model, every experiment, every real-time recommendation or generative AI application demands vast, ever-changing datasets. ETL pipelines suddenly became a bottleneck, struggling to keep up with the velocity and variety of new data. Additionally, once data landed in the warehouse, it was effectively locked into a predefined schema and a set of transformations. Plus, if we need to make that data available in another system, it required repeating the ETL process, introducing delays, duplication and maintenance overhead.
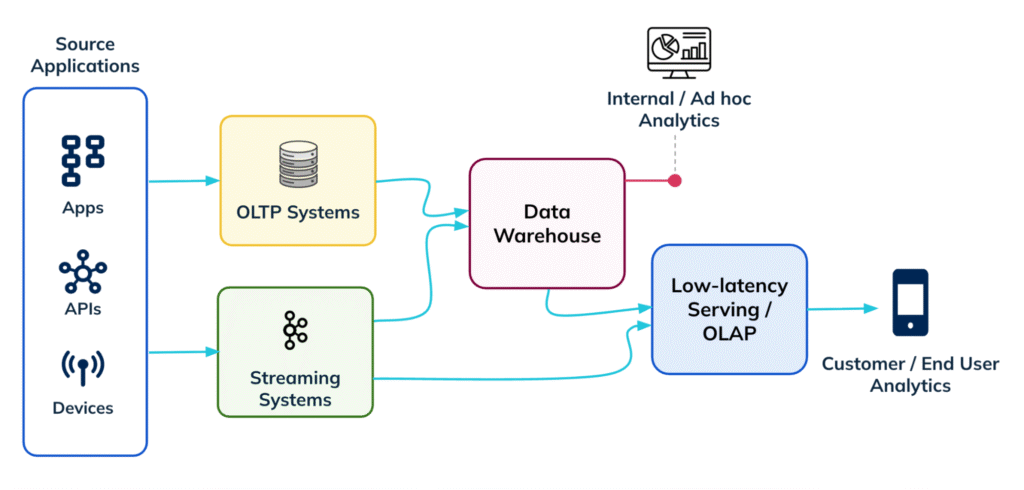
About a decade or so ago, a new set of use cases began to emerge in analytics – Serving. Unlike traditional analytics, which primarily focused on historical insights, serving aimed to put analytics directly into the hands of users and applications. This included powering end-user dashboards that update instantly, enabling personalized experiences, and providing live metrics for operational decision-making. The rise of serving workloads gave birth to OLAP and, in particular, real-time analytics databases such as Apache Pinot, ClickHouse, and others, which were purpose-built to handle the high concurrency and extremely low-latency queries these use cases demanded. While many of these systems ingested data in real time, they also often relied on ETL, either directly from sources or through reverse ETL from data warehouses, running in parallel with existing pipelines and further compounding the operational challenges associated with ETL.
Organizations needed a way to make data more accessible without constantly moving and transforming it. This need gave rise to data lakes. By storing raw data centrally and deferring transformations, data lakes provided both flexibility and a single source of truth. Data formats also became standardized, with Parquet emerging as the widely adopted choice. Analysts, data warehouses, serving layers, and Spark jobs could all work from the same dataset, reducing duplication and making access more streamlined and efficient.
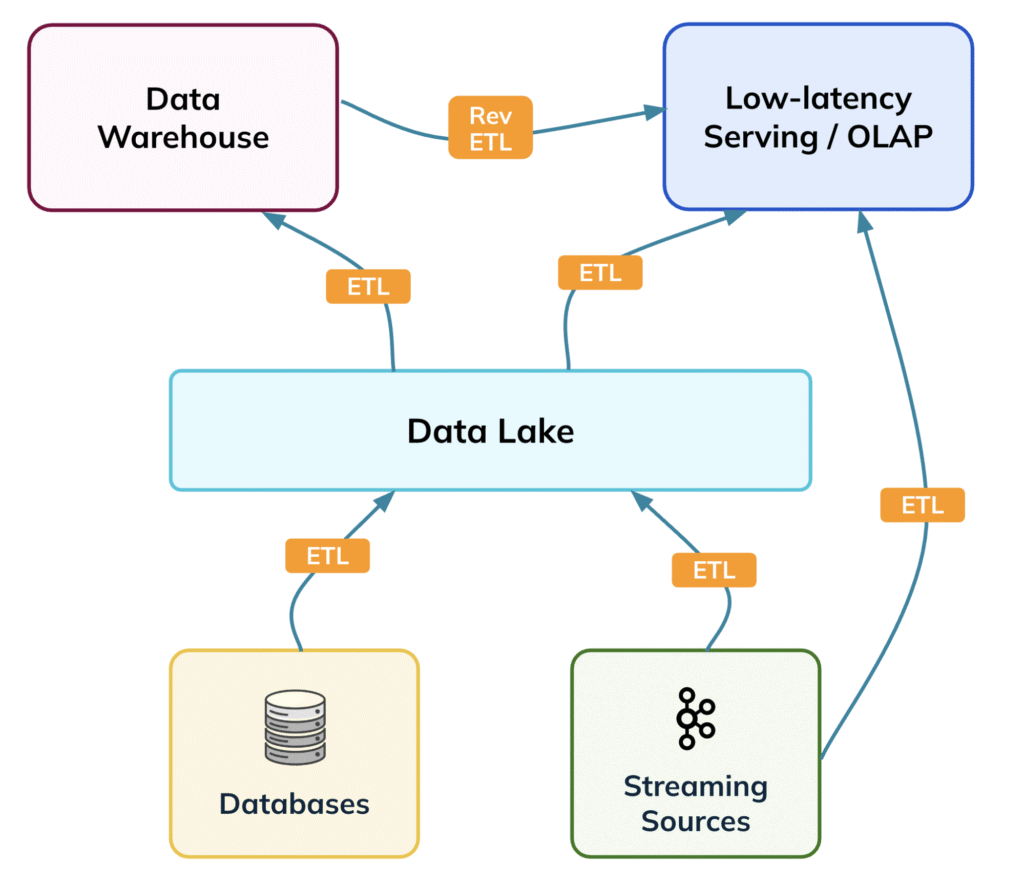
While data lakes helped simplify some challenges, they didn’t eliminate ETL entirely. Data warehouses still relied on transformed data, and serving layers still needed their own ingested copies. In other words, moving data around remained unavoidable. The solution, however, was right in front of us: instead of repeatedly transforming and moving data, why not query it directly from the lake?
Iceberg – the open-source table format built on top of data lakes was a key step toward solving this challenge. It brought structure and standardization to raw lake storage, while enabling features like schema evolution, partitioning, and metadata management directly on the lake. Essentially, Iceberg bridged the gap between raw data and structured processing. Data warehouses quickly adopted Iceberg, allowing them to read and process data directly from the lake without relying on cumbersome ingestion pipelines. This ability to query the lake directly, bypassing repeated ETL, was transformational, rapidly establishing Iceberg as a foundational technology for historical, ad-hoc, and batch analytics.
And this brings us to the next natural question, wouldn’t serving systems also benefit from adopting this? The answer is of course, yes, however, the problem is intrinsically much harder in systems purpose built for serving.
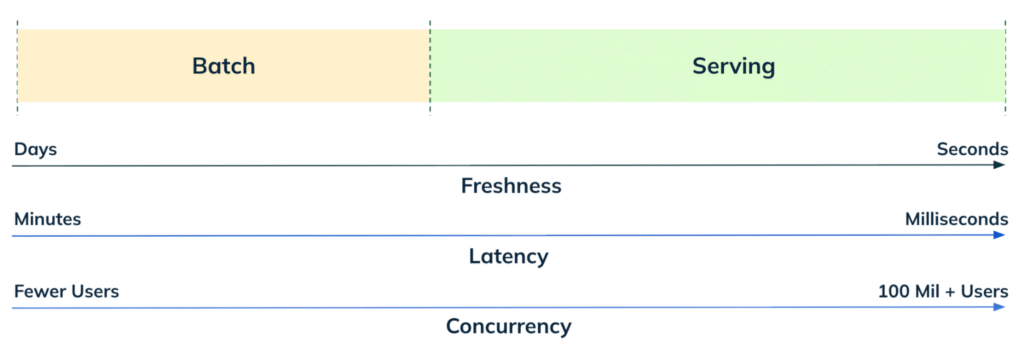
Data warehouses are inherently designed as powerful scan engines, optimized for workloads that are scan-heavy in nature. While the data processed per query is large, the concurrency is relatively low, and latency expectations are relaxed (tens of concurrent users, seconds latency). Serving use cases, on the other hand, operate under a completely different set of constraints. Interactive and end-user facing experiences such as personalized recommendations on a meal delivery app or live transaction metrics on a merchant dashboard require lightning-fast responses for all active users on the platforms. Take Apache Pinot as an example: workloads of tens of thousands of queries per second, ingesting millions of events per second, and serving results at millisecond latency are the norm.
In Apache Pinot, this is achieved through a combination of design choices. One key element is the optimized custom columnar file format. Even more important, however, is Pinot’s index-first design philosophy: Pinot has an army of indexes, right from the classic inverted, sorted indexes, all the way to specialized indexes like range, text, json, geospatial and vector. The goal is to scan less and fetch only the precise bytes needed. This approach is what enables Pinot to reach unprecedented scale, consistently outperforming benchmarks for low-latency, high-throughput analytics. Such precision reads become even more critical when a database needs to serve directly from a data lake, and using open file formats.
Low latency serving on Iceberg, with Apache Pinot on StarTree Cloud
We’re pleased to announce that Apache Pinot now supports querying Iceberg tables natively via StarTree Cloud, a cloud native managed platform for Pinot. This means that Pinot can connect directly to Iceberg tables without the need for explicit data ingestion and conversion to Pinot segments. While it now joins the ranks of databases with Iceberg support, Pinot stands out: just as it defined the category of end-user facing real-time analytics and became a leader in low-latency analytics serving, it is now the first to pave the way for low-latency serving on the data-lake, an area that had remained unventured so far.

But how did we do it? We just read above that the Pinot’s performance comes from its highly optimized custom file format and gamut of indexes. But with Iceberg format, we’re now operating with raw parquet files directly over the data lake. Let’s explore the key building blocks that made this possible and trace the evolution of Pinot itself during this journey.
The evolution from compute-storage tightly-coupled to decoupled
When Pinot was created over a decade ago, it began as a tightly coupled system. Users loved the speed, and as adoption grew, many wanted to keep all their data in Pinot, both real-time and historical. However, the tightly coupled storage model quickly became cost-prohibitive for large retention. Ideally, users wanted the best of both worlds: the speed of a tightly coupled architecture and the cost efficiency of a decoupled system. This challenge prompted a major evolution in Pinot moving from local-only storage to supporting cloud object storage.
Cloud-native querying commonly known as tiered storage is supported by many systems today and is no longer a novel feature. However, the architectural choices ultimately determine how far performance can be pushed, which is especially crucial for a serving system. Accessing S3 is inherently slow: what takes microseconds or a few milliseconds on SSDs or disks can become a network call taking hundreds of milliseconds. Most systems with cloud-native querying rely on lazy loading, fetching entire data shards to local disk on first access and hoping they can be reused for subsequent queries. While this approach may work for batch analytics that read contiguous ranges of data, low-latency analytics workloads are different: they involve point lookups and arbitrary slice-and-dice operations on frequently changing attributes, making reuse of downloaded data rare. Serving use cases also require predictable p99 latencies, which are hard to guarantee when large volumes of data may need to be fetched. This approach is therefore far from ideal for low-latency, high-concurrency serving.
Pinot’s tiered storage design goes far beyond simple lazy loading, enabling precise and efficient reads directly from object stores:
Low-granularity block reads:
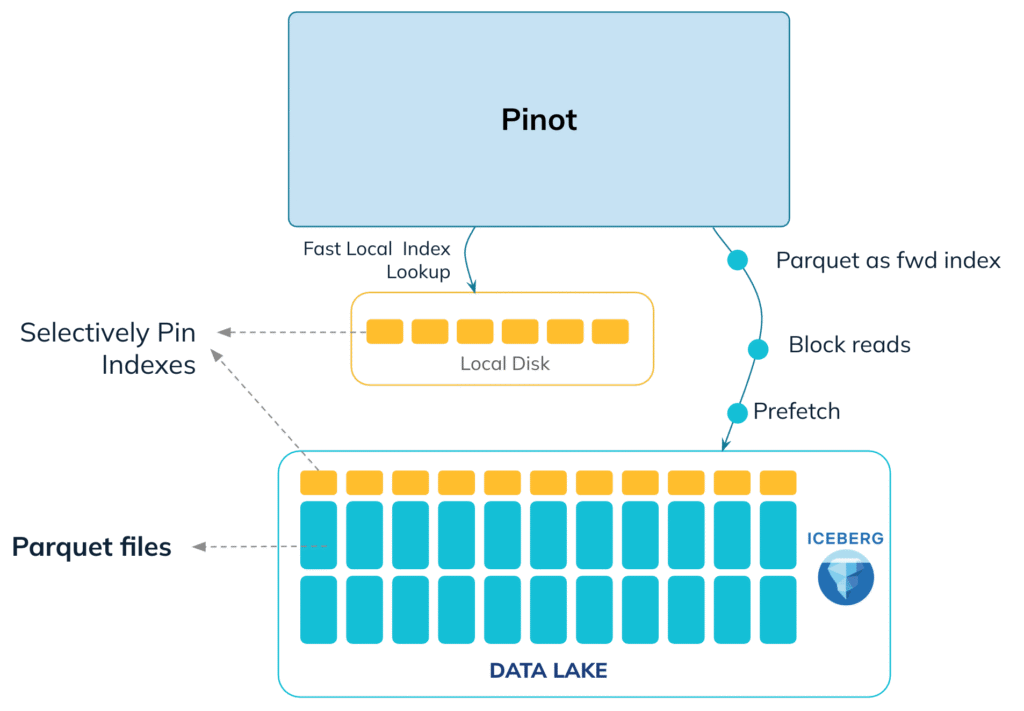
We never download an entire segment file, or even a full column. Leveraging the columnar nature of the Pinot file format, we can pinpoint exactly where the required column resides. We then fetch only the precise blocks within a column needed for the query, using targeted range GET requests to the files on S3.
Parallel access:
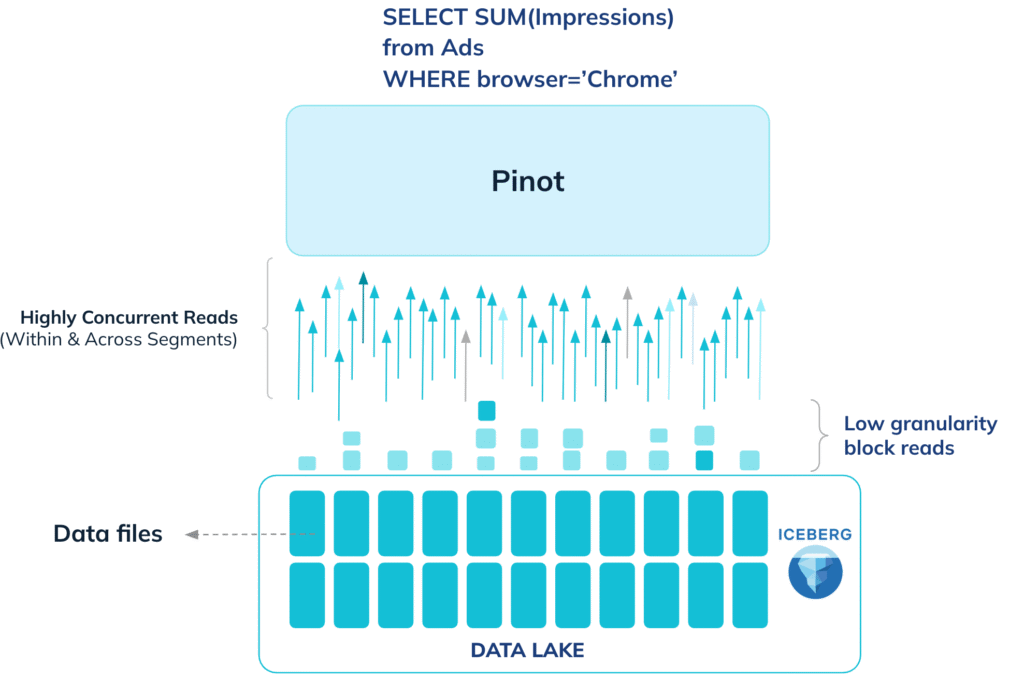
S3 excels at high-concurrency reads, and we exploit this fully. All block reads are dispatched in parallel until the network is saturated, maximizing throughput.
Prefetching:
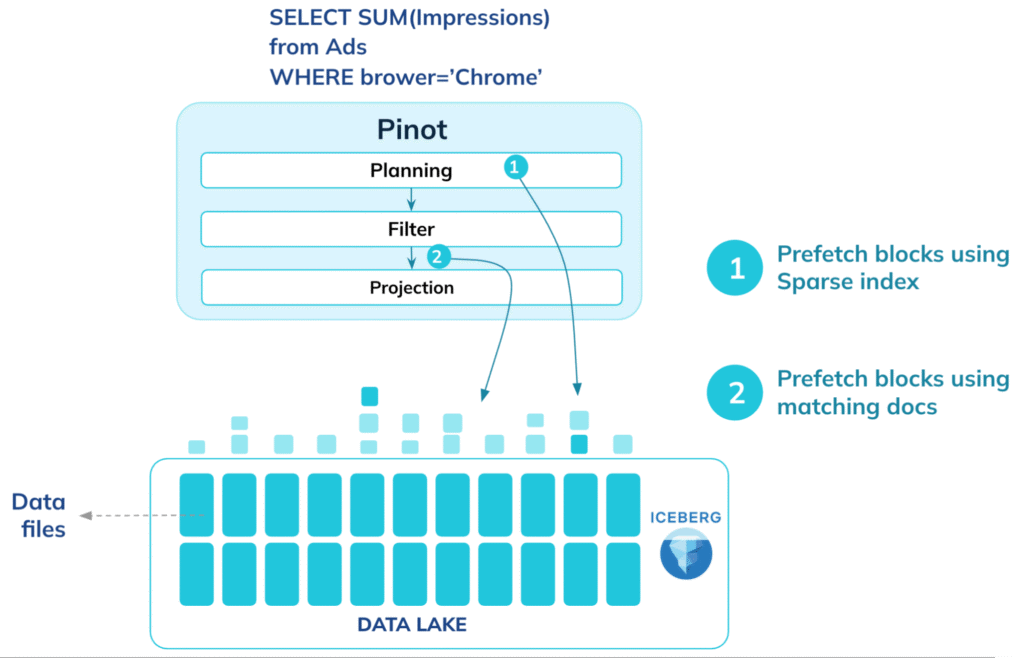
Whenever the query allows, we prefetch all necessary blocks and pipeline their fetching with query execution. During the planning phase, Pinot uses sparse indexes and metadata to identify the blocks needed post-filter, allowing prefetching to begin proactively.
The evolution from Pinot segment format to Parquet
With cloud-native querying built into Pinot and optimized for serving, we were ready for the next leap: native Parquet support.
We introduced a Parquet forward index reader to enable reading directly from Parquet. To understand how we designed this, let’s look at the Pinot segment layout. A Pinot segment is generally composed of a forward index for every column, with additional indexes built on top of it. Leveraging the forward index abstraction, we created a new forward index implementation that works directly on Parquet columns. This allows Pinot to serve data from Parquet natively, without any file format conversion.

The evolution of indexes for full spectrum of flexibility
Pruning techniques, which leverage metadata provided by Parquet, can help reduce the amount of data that needs to be scanned. Iceberg makes these techniques even more accessible by providing file-level statistics that enable further pruning. This is the extent of the optimization in other systems providing Iceberg table support. Most systems supporting Iceberg tables stop here. However, even with these optimizations, full files often still need to be accessed, resulting in unnecessary network load and expensive, wasteful data transfers.
With Parquet support integrated into the Pinot forward index abstraction, we unlocked the key to what makes Pinot fast: its indexes. In Pinot, indexes depend only on the forward index interface, not on the Pinot file format. As a result, all of Pinot’s existing indexes work seamlessly on top of the new Parquet forward index implementation, an achievement made possible only by a design built on strong interfaces and pluggability.
After making indexes work with the Parquet format, the next step was to make them optimally usable with cloud-native querying. To achieve this, we built the capability to pin indexes locally. This gives us the flexibility to choose which indexes should be read directly from cloud storage and which should be read locally for faster access, depending on the performance needs of different query patterns. Indexes are typically a small fraction of the data, so pinning them locally is an inexpensive tradeoff. These pinned indexes quickly identify the exact document IDs that match a query, helping us avoid scanning large portions of data and enabling highly precise block reads directly from the object store. Pinot allows pinning of every index, including dictionaries and forward indexes and can also leverage segment-level indexes, like StarTree indexes, by pinning them partially or entirely when needed.
Unlocking a full spectrum of choice
The most powerful aspect of Pinot’s architecture is the full spectrum of choice it offers that lets you pick the most suitable option between each of these
- storage tier – from SSDs to traditional disks to cloud object stores.
- file format – from highly optimized custom formats to open standards like Parquet.
- indexing strategies – from no indexes at all to fully indexed data.
This flexibility lets you configure Pinot to meet your specific performance and cost trade-offs, giving you control over how you balance speed, concurrency, and storage efficiency.
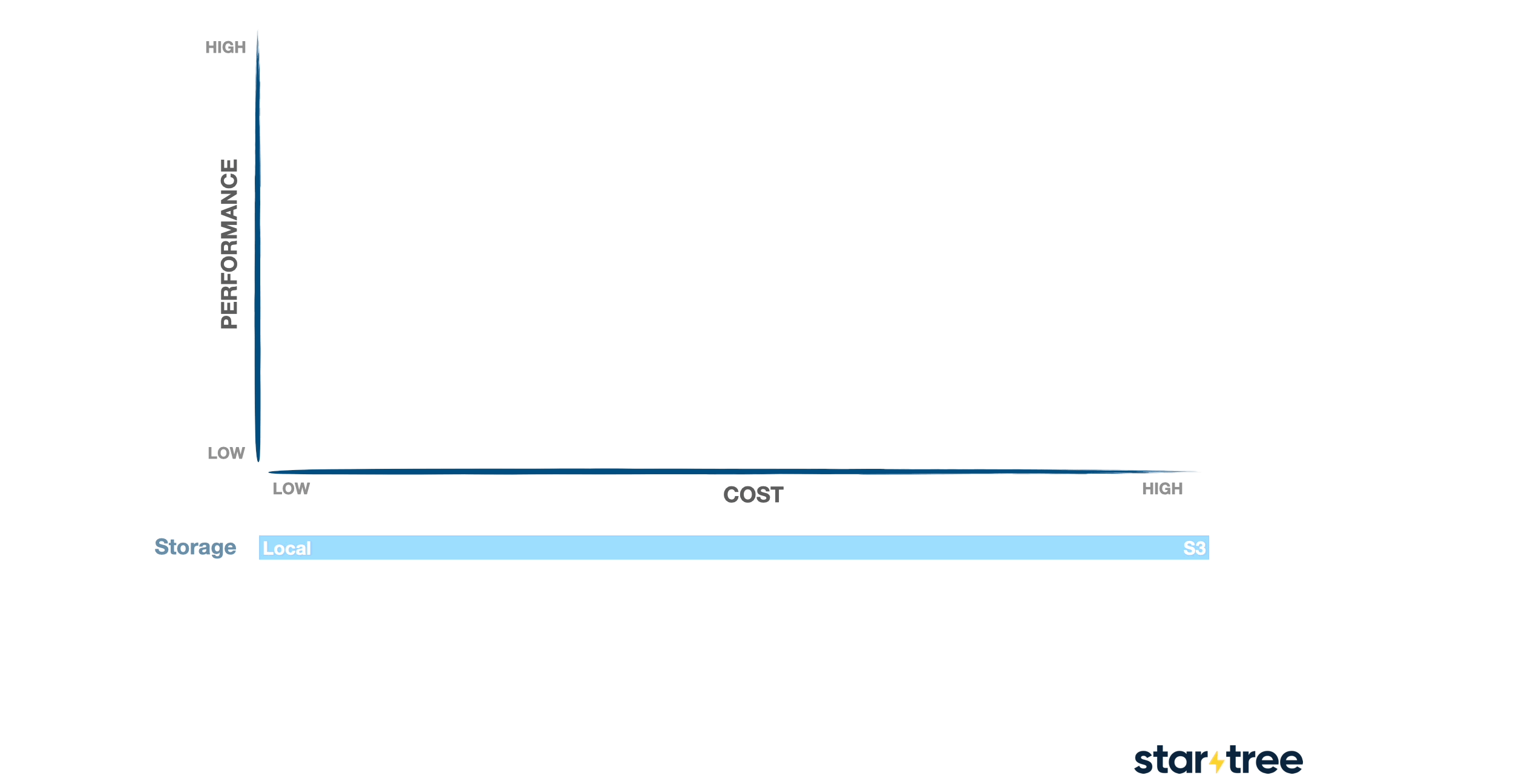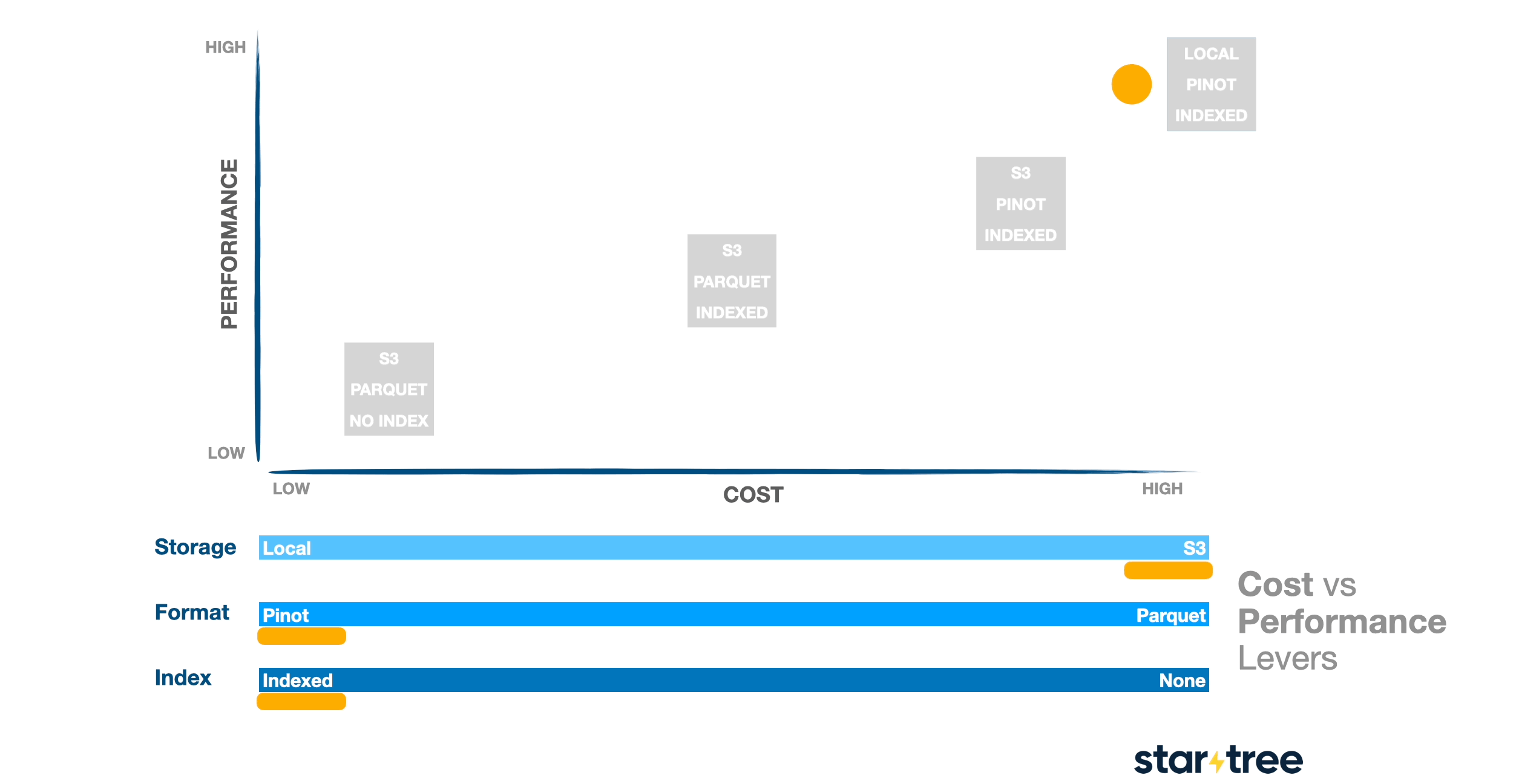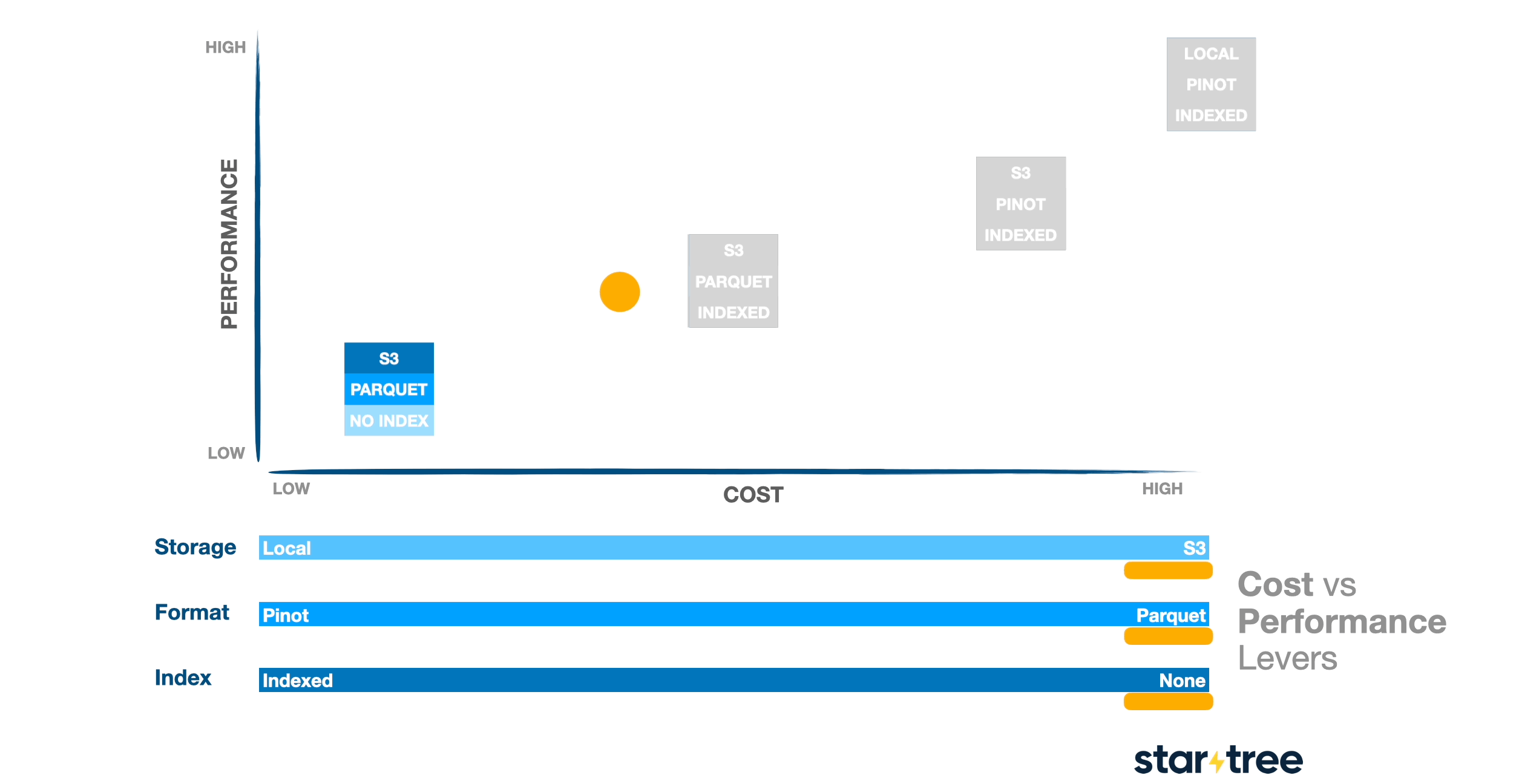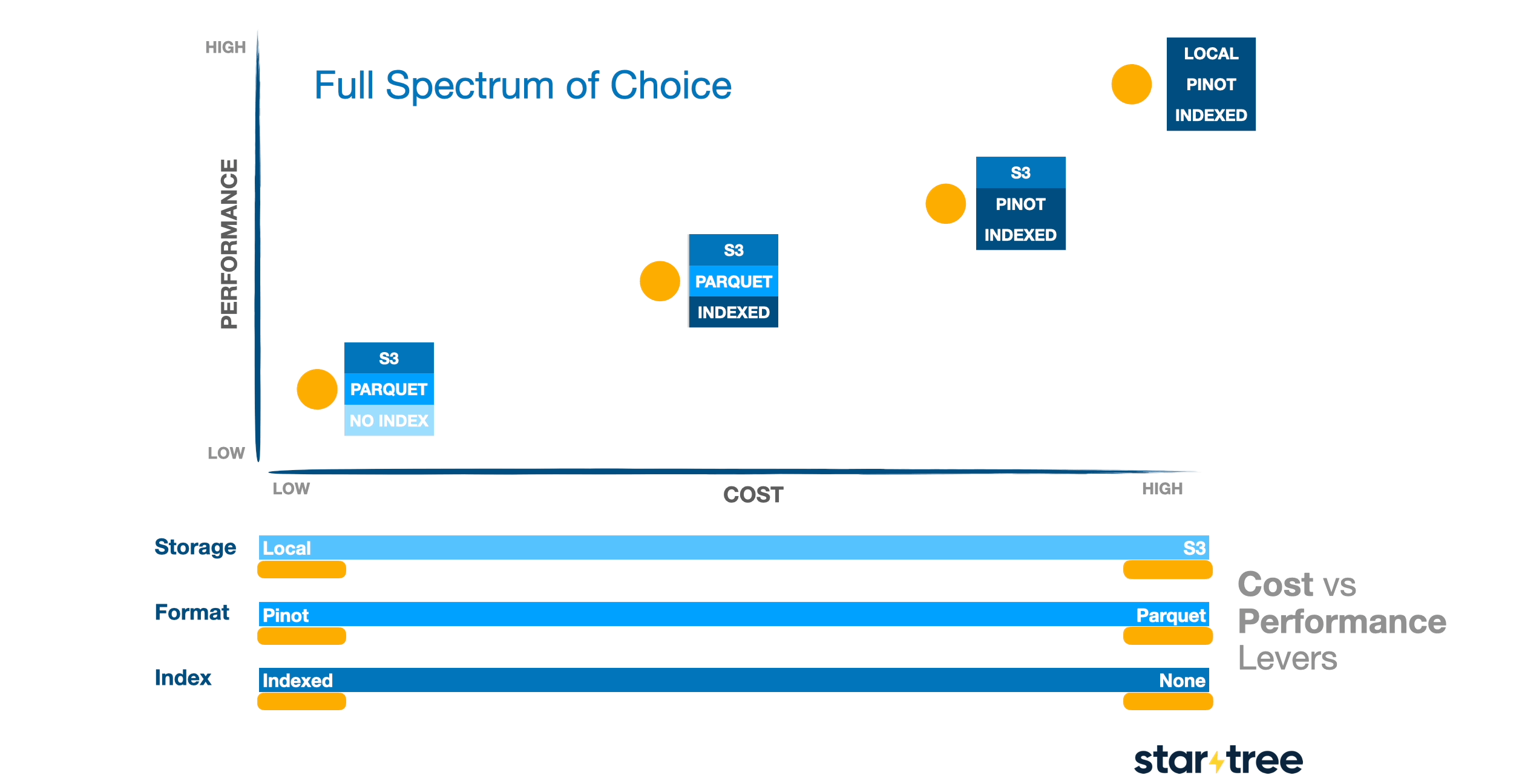
Conclusion
With native Iceberg support, Apache Pinot becomes the first system to offer a true low-latency serving layer directly on the data lake. Leveraging its index-first architecture, forward index abstraction, and tiered storage design, Pinot can serve queries on open formats like Parquet with millisecond latency without ETL or data duplication, unlocking the full power of low-latency analytics on Iceberg tables.
Stay tuned for part two of this blog, where we will dive even deeper into the design decisions, the complexity and our implementation. A huge shout out to the team working on making this possible – Raghav Yadav, Sonam Mandal, Songqiao Su and Kishore Gopalakrishna, and to Bhavani Akunuri and Chinmay Soman for helping with this blog!
Connect with us
Millions of concurrent users. Tens of thousands of queries per second. Hundreds of thousands of events flowing every second. If these are the kinds of numbers you operate with, aspire to handle, or are simply curious about, let’s connect! We’d love to share our lessons in serving at scale, hear your use cases, and geek out over low-latency analytics.
- Join the community slack Apache Pinot, StarTree Community
- Follow our adventures on LinkedIn StarTree
- Catch us on X Apache Pinot, StarTree
