
In Part 1, we followed the bytes: Kafka partitions → consume loop → mutable segments → flush thresholds → immutable segment build.
But Pinot never flies solo.
Realtime tables typically run with multiple replicas consuming the same Kafka partition. That means multiple servers can reach a flush boundary around the same time with slightly different offsets, different build times and sometimes different failure modes. At that moment, Pinot needs one authoritative answer to a deceptively simple question: Which exact slice of the stream should be the one true segment consistent across all replicas?
This is where the controller becomes air-traffic control. In this post, we’ll dive into server↔controller communication and the blocking commit protocol Pinot uses to coordinate a single, consistent commit across replicas.
We’ll stick to the classic protocol here. Pauseless consumption deserves its own chapter.
Coordinated flight: why consensus matters at scale
At our largest customer deployments processing tens of millions of events per second with sub second freshness requirements, the commit protocol is the make or break moment for data integrity. Imagine three replicas each building their own version of a segment, each with slightly different end offsets due to timing variations. Without coordination, you’d have three different “truths”, a recipe for inconsistent query results and debugging nightmares.
Traditional databases handle this with heavyweight consensus protocols at the transaction level, ensuring every write is replicated and committed consistently before becoming visible. Kafka Streams relies on consumer group coordination and changelog topics. Flink uses distributed snapshots with barrier alignment.
Pinot operates at a much coarser granularity. Instead of coordinating individual records, it coordinates mutable segments. A controller driven finite state machine selects a single committer and a single winning end offset per segment. The unit of agreement is not a row or a transaction, but a slice of the stream. This protocol is triggered only at segment boundaries and not per event. This allows each server to consume at high throughput without worrying about convergence until a good enough chunk of data is consumed.
It’s not flashy, but for high throughput ingestion it delivers exactly what you want: predictable convergence under stress.
Hailing the right tower
Before we even talk about commit, we need to talk about leadership.
Segment completion requests must go to the controller that is the leader for that table. On the server side, ControllerLeaderLocator caches the leader’s host and refreshes it from Helix when needed.
The protocol also includes a NOT_LEADER response. Servers treat it as: “you called the wrong leader, recheck who’s the real one.”
A subtle but important detail: the server also invalidates the cached leader on any communication errors because failures often correlate with controller failover. That prevents the cluster from getting stuck repeatedly calling a dead leader.
Ground control: who talks to whom?
Let’s name the actors:
Servers are the ones consuming Kafka and building segments via RealtimeSegmentDataManager
The Controller is the coordinator that decides who is allowed to commit, what the winning end offset is, and when to publish the sealed segment and spawn the next consuming segment.
On the wire, this coordination is implemented as the SegmentCompletionProtocol and driven on the controller by a per-segment finite state machine (FSM) managed by SegmentCompletionManager.
An FSM is simply a structured state transition model. For each segment, the controller tracks its current coordination state (e.g., HOLDING, COMMITTER_DECIDED, COMMITTING, COMMITTED, ABORTED) and only allows transitions that are valid from that state. This matters because committing a segment can involve retries, leader changes, timeouts, and competing replicas. The FSM ensures that even under this chaos, only one valid commit path can succeed and illegal transitions are rejected deterministically.
On the server side, requests are sent via ServerSegmentCompletionProtocolHandler.
Think of this as a lightweight, purpose-built “commit control plane” layered on top of Helix + ZooKeeper.
Radio check: segmentConsumed drives the controller FSM
In the blocking protocol, the controller’s FSM is clocked by the servers. There’s no timer thread inside the FSM. Instead, servers keep resending status until the controller tells them what to do.
The heartbeat message is segmentConsumed (HTTP GET), which includes the segment name, instance id, current offset, and a “stop reason” which indicates if the we are stopped consuming either due to reaching any of the configured flush thresholds or due to some error.
On the controller side, SegmentCompletionManager.segmentConsumed() checks: “Am I the leader for this table?” and “Am I connected to Helix?” If either answer is “no”, it returns NOT_LEADER. If “yes”, it routes the message into the per-segment FSM instance. If the FSM instance does not exist, it creates a new one.
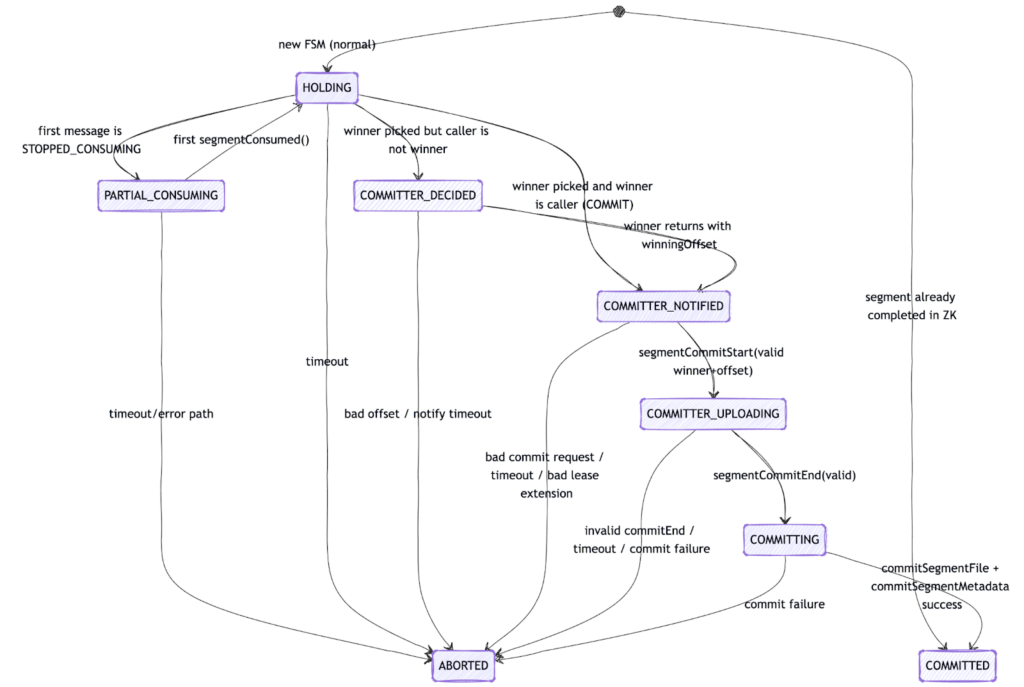
This diagram above shows the controller-side finite state machine (FSM) for a single segment and a single partition.
Each box represents a coordination state. Arrows represent valid transitions triggered by server requests, timeouts, or validation checks. The FSM ensures that only one commit path can successfully reach COMMITTED.
At a high level, the flow is:
- HOLDING – The controller is waiting to hear from replicas.
- COMMITTER_DECIDED – A winner and winning offset have been chosen.
- COMMITTER_NOTIFIED – The winner has been told to commit.
- COMMITTER_UPLOADING – The committer has started the commit sequence and is uploading the segment.
- COMMITTING – The controller is finalizing metadata updates in Zookeeper and publication.
- COMMITTED – The segment is successfully published.
Any validation failure, timeout, bad offset, or lease issue transitions the FSM to ABORTED, forcing replicas back into the HOLD-driven retry loop.
Two important properties to notice:
- Only the elected winner can advance through the upload and commit states.
- Every transition is validated against the expected winner and winning offset.
This is how Pinot guarantees that even under retries, partial failures, or controller changes, at most one commit path can succeed.
Tower instructions: the vocabulary that keeps clusters consistent
Upon receiving a segment consumed message, the controller responds with a compact set of statuses. The key ones for the blocking protocol are:
- HOLD – This means that the controller needs to hear from more servers or time and hasn’t reached a decision. Upon receiving this servers typically sleep up to MAX_HOLD_TIME_MS and retry.
- COMMIT – You are the committer. Build the segment and start the commit sequence
- CATCH_UP – You’re behind the winning offset. Keep consuming until you reach it.
- KEEP – You already have the winning slice; build and keep your local segment.
- DISCARD – Your slice doesn’t match; drop it and download the committed segment from deep store
This set is intentionally minimal. Pinot does not run a general purpose, multi phase consensus protocol during segment completion. There is no replicated log agreement or majority voting per event. Instead, the controller drives a deterministic state machine, selects a single committer, and instructs all other replicas how to converge.
Agreement happens once per segment, not per record and the coordination vocabulary is deliberately small to ensure predictable convergence under stress.
How the controller picks a committer
When replicas for a given partition hit a flush boundary (row count, time threshold, or segment size), they stop consuming and report their offsets to the controller in a segmentConsumed message. The controller maintains a map of instance → offset and then picks a winning offset and a winner instance (the committer).
The “fast path” winner
If the stop reason is reaching the configured flush row count, or the partition has no more data and the controller has only heard from a single replica, the controller can immediately select that first reporter as the winner. These scenarios are deterministic enough that other replicas are expected to stop at the same boundary, and even if they do not, the FSM has safeguards to handle the divergence.
The “wait a bit” winner
The controller waits until either enough time has passed or it has heard from all replicas. Then it picks the maximum offset reported as the winning offset. If there are multiple replicas with the same maximum offset, it picks up whoever reported the last.
This “max offset wins” rule is the core of correctness for the blocking protocol: it forces the cluster to converge on a single end offset even when replicas drift slightly.
Holding pattern: why ingestion pauses
Once a segment for a given stream partition hits its flush boundary, that partition is no longer just ingesting. It enters a coordination phase:
- Stop consuming new events for that partition’s current segment
- Ask the controller what to do
- If chosen as committer, build an immutable segment
- Commit and publish it
- Only then does that partition’s consuming frontier advance
Other partitions continue ingesting and committing independently in parallel.
This is the tradeoff: the protocol is simple and robust, but the chosen committer replica is “busy” during commit. In production deployments handling hundreds of partitions, this pause is typically measured in seconds for that partition which is acceptable for most use cases, but noticeable when chasing single-digit second freshness at massive scale. Pauseless consumption exists specifically to reduce this partition level pause, but we’ll keep that out of scope for this post.
Final approach: commitStart → upload → commitEnd
Once the controller responds with COMMIT, the server transitions into the commit sequence. This involves converting the segment from its mutable state to an immutable state on disk along with adding indices such as Startree that require a complete view of segment data.
In current Pinot code, even the “blocking” flow uses a split commit style on the wire, implemented by SplitSegmentCommitter.
1) segmentCommitStart
The committer calls segmentCommitStart. If the controller accepts this commit attempt, it returns COMMIT_CONTINUE basically saying: “Yes, you are still the winner, proceed with uploading.”
If the controller rejects it due to either invalid state transition in FSM, reported offset being different from winning, too late in reverting to COMMIT call, etc.), the server falls back into HOLD and retries the coordination loop.
2) Upload the segment bytes
Next, the committer uploads the segment tarball. Where it uploads depends on configuration:
Upload to deep store – the server uploads to a configured URI e.g., S3/GCS/HDFS. This is the default in all our production environments.
Upload via the controller – This is the legacy approach where we upload segments to the pinot controller and then it takes care of moving the segment to deep store / servers. We do not recommend this now since it leads to extremely high load on controllers.
Either way, the outcome is the same: the server ends up with a URI that identifies where the committed segment can be downloaded from.
3) segmentCommitEndWithMetadata
Finally, the committer calls segmentCommitEndWithMetadata. This request includes the instance id, segment name, stream partition end offset, stop reason + timing stats (build/wait time), segment size / memory hints, the segmentLocation URI, and metadata files.
If everything succeeds, the controller responds with COMMIT_SUCCESS. At this point, the committer is done. The controller is now responsible for publishing the committed segment and advancing the table.
Touchdown: what happens on COMMIT_SUCCESS
Inside the controller, the commit end call funnels into SegmentCompletionManager.segmentCommitEnd() which performs the commit under strict checks: “Are we in the expected FSM state?”, “Is this instance the winner?”, and “Does the offset match the winning offset?”
If any of those checks fail, the FSM aborts and forces servers back into HOLD, effectively restarting coordination to regain consistency.
When the checks pass, the controller commits in two major steps:
Step A: Commit/move the segment file
PinotLLCRealtimeSegmentManager.commitSegmentFile() ensures the segment is in the right permanent place. If the segmentLocation points to a temporary upload name, the controller moves it into its final location under the table’s segment directory.
Step B: Commit segment metadata + advance the consuming frontier
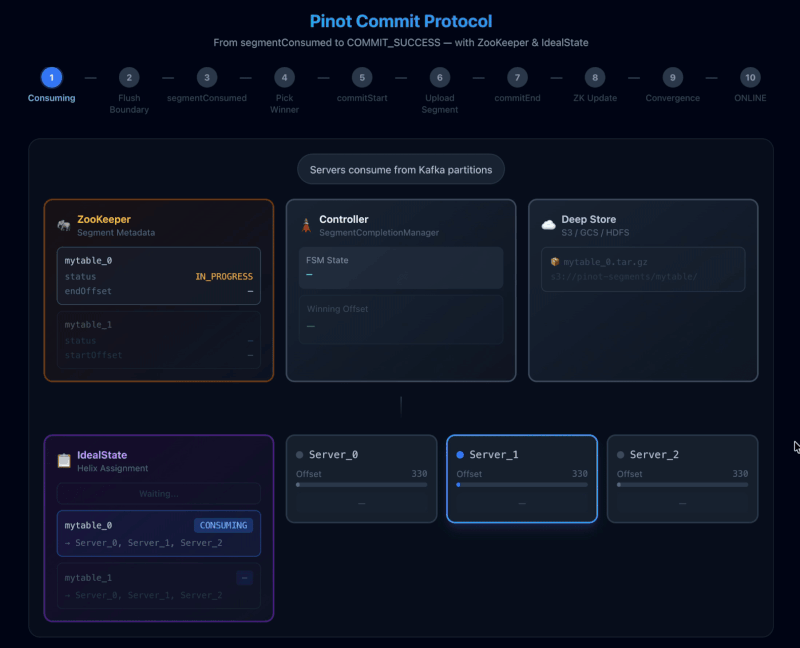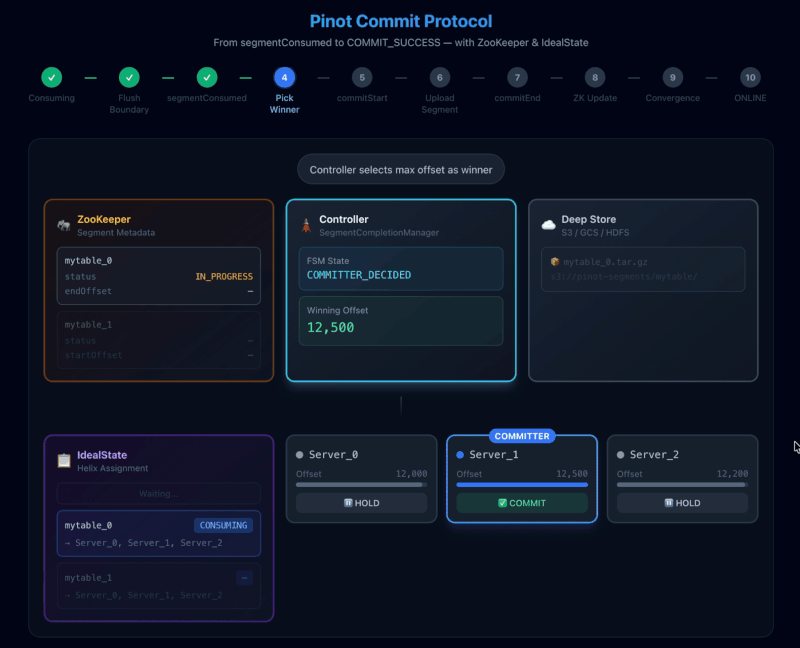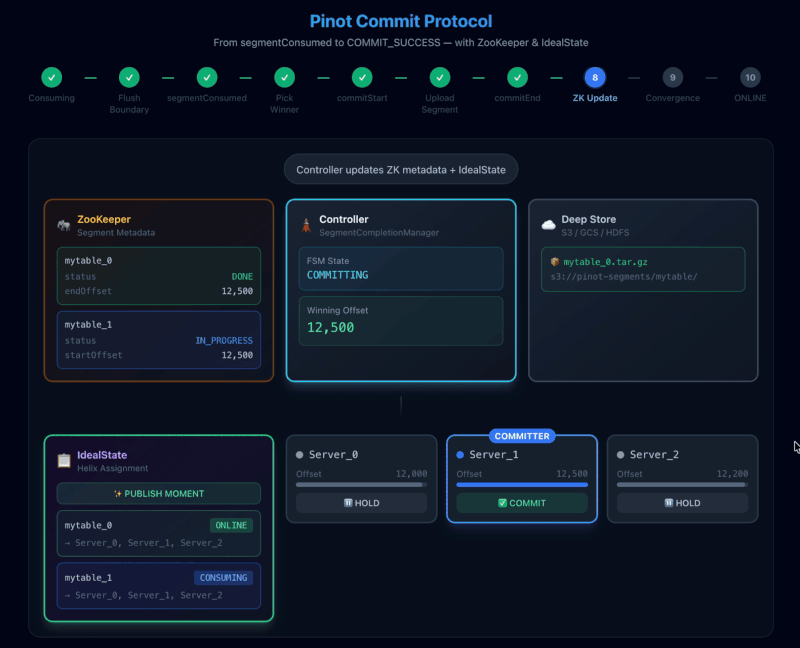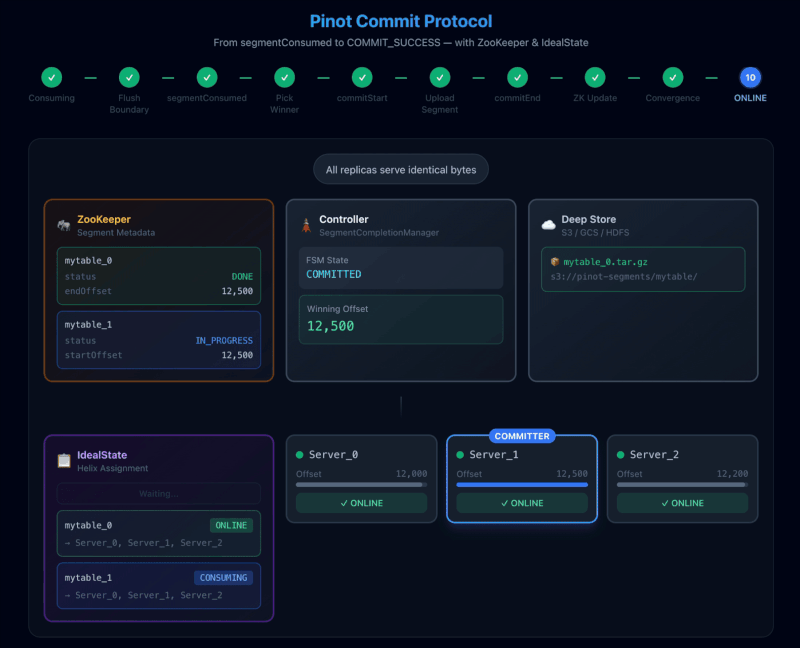
PinotLLCRealtimeSegmentManager.commitSegmentMetadata() updates ZooKeeper/Helix in a carefully ordered sequence:
- Update the committing segment’s ZK metadata from IN_PROGRESS to DONE and update segment URI in it.
- Create ZK metadata for the next consuming segment
- Update the table’s IdealState: committing segment moves to ONLINE, new segment enters CONSUMING
That final IdealState update is the “publish moment.” It’s what causes the cluster to treat the segment as committed and queryable.
The rest of the squadron: non-committer convergence
The other replicas keep sending segmentConsumed and receive controller instructions:
- If they are behind, the controller sends
CATCH_UP.This means you should consume missing data till the winning offset - If they match the winning offset but the commit hasn’t finished: HOLD
- After commit: typically
KEEPif they have already consumed till the winning offset, otherwiseDISCARD
Separately, once IdealState flips the segment to ONLINE, the non-committers converge by downloading the committed segment using URI in the ZK metadata if they were instructed to DISCARD their own segment.
This is how Pinot avoids the nightmare scenario where two replicas “successfully” commit two different end offsets for the same segment name.
Turbulence protocols: staying sane under chaos
Distributed systems don’t fail politely. The blocking protocol bakes in a few pragmatic guardrails:
Leader fencing – non-leader controllers answer NOT_LEADER
Time bounds – the FSM aborts if it takes too long to pick/notify/commit
Winner verification – the instance and offset in commit start/end messages must match the chosen winner + winning offset in FSM.
Abort-and-retry – on inconsistencies, the FSM enters ABORTED and forces the servers back into a HOLD-driven retry loop
It’s not flashy, but it’s exactly what you want for ingestion i.e. predictable convergence under stress.
Mission accomplished (for now)
We’ve now covered the part of ingestion that turns “I built a segment” into “the cluster agrees this segment exists.”
Servers report offsets and stop reasons via segmentConsumed. The controller picks a winner and a winning offset. One committer runs the sequence: commitStart → upload → commitEnd. The controller publishes by updating ZK metadata and IdealState. Everyone else converges to the committed bytes.
This design enables parallel replica consumption with minimal coordination on the hot path. Replicas ingest independently and only synchronize at segment boundaries. The controller driven FSM keeps coordination deterministic and bounded, avoiding heavyweight per record consensus.
The result is a system that scales horizontally across partitions, requires agreement sparingly, and remains failure- resilient under retries, leader changes, and partial crashes.
In the next chapter, we’ll look at how Pinot reduces the “blocking” nature of this flow with pauseless consumption and why that matters when you’re chasing single digit second freshness at scale.
