
Time-sensitivity creates a natural hierarchy of data value. Recent data provides more value—it’s frequently queried, demands real-time responsiveness, and justifies investment in high-performance storage infrastructure. In contrast, historical data presents a different value proposition. While still valuable for longitudinal analysis and compliance, it faces less frequent access despite continuously expanding volume, making cost-efficiency the dominant consideration.
| Recent Data | Historical Data |
|---|---|
| High query frequency | Accessed less frequently |
| Requires real-time responsiveness | Valuable for longitudinal analysis and compliance |
| Justifies expense of high-performance storage | Cost efficiency is a key factor |
This tension places organizations in an ongoing strategic dilemma. They must choose between allocating resources to expensive, high-performance local storage that delivers the speed real-time analytics demands, or leveraging more economical object storage options that sacrifice query performance. This forces consequential decisions about data lifecycle management—what to keep readily accessible, what to archive in cold storage, and what to ultimately purge from systems entirely.
Improve query performance with Precise Fetching in StarTree
StarTree Cloud is a real-time analytics platform powered by Apache Pinot. It extends the capabilities of Apache Pinot’s inherent tiered storage architecture by allowing the storage of data on object stores such as Amazon S3, Google Cloud Storage or Azure Blob Storage. Let’s dive into the technical implementation details to understand how it achieves optimum performance.
StarTree’s Precise Fetching significantly reduces the tradeoff between cost and query performance. By minimizing the amount of data moved from object storage to compute, Precise Fetching in tiered storage delivers interactive query performance on historical data without the premium cost of local storage. This approach allows StarTree’s customers to reduce infrastructure costs by more than half while maintaining fast query latencies across their data.
Local vs. Object Storage
Most organizations try to solve the performance vs. cost dilemma with hybrid systems—high-performance local storage for recent data and object storage for historical data.
| Hot Storage (Local) | Cold Storage (Object Storage) | |
| Advantages | Fast queries with millisecond-level latency | Much cheaper |
| Disadvantages | Expensive, tight coupling of storage and compute | Traditionally slower access speeds, higher latency |
| Use Case | Real-time analytics requiring sub-second responses | Historical data, less frequently accessed information |
| Cost | Generally high | Significantly lower than hot storage |
Object storage offers compelling economics for analytical data, since it’s cheaper than local high-performance storage. However, most organizations can’t fully leverage object storage for interactive analytics because of the performance penalty caused by inefficient data movement.
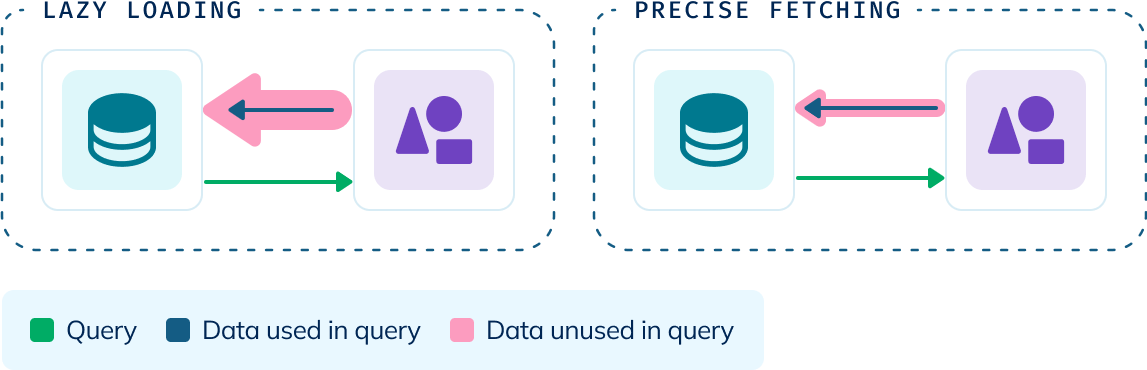
Object Storage & Analytics: The Lazy Loading Problem
Object storage isn’t inherently slow. The actual bottleneck is the inefficient data movement between storage and compute layers.
The main issue involves how systems must transfer data from object storage to local compute resources for processing. When a query needs information from cold storage, the entire data movement process creates significant I/O overhead.
In most OLAP systems, ‘lazy loading’ moves data from object storage to compute—retrieving the specific partition that contains the requested data, but it also loads additional data within that partition, including data not needed for the current query.
Here’s how lazy loading typically works:
- A query requests specific data located in object storage
- The system downloads the specific partition containing the requested data
- The requested partition is loaded into local memory/storage, which includes both the data needed for the query and other data that happens to be in the same partition
- The query processes the requested data locally, while the other data in the partition remains unused but still consumes resources
This approach creates inefficiencies:
- Excessive data movement: Even if a query only needs a small fraction of the data (perhaps just a few columns or rows), systems load additional data that isn’t needed for the current query
- High bandwidth consumption: Moving large volumes of unnecessary data wastes network resources
- Increased latency: Users experience slower query performance due to the wait for data transfer
- Higher costs: Processing and moving excess data consumes more computational resources
As data volumes grow to petabyte-scale, these inefficiencies become increasingly problematic. More data means more partitions, more transfers, more processing, and ultimately, more costs and longer wait times.
StarTree’s Solution: Precise Fetching
Precise Fetching in StarTree’s tiered storage solves the issue of I/O overhead by determining exactly what data is needed for the query and fetching only those specific components, making object storage a viable option for performance-sensitive analytics. Instead of lazily loading partitions, StarTree implements Precise Fetching—a technique that minimizes unnecessary data movement by enabling you to query object storage with significantly improved latency compared to traditional approaches, giving you both interactive query speeds and cost efficiency in a single system.
The core idea is simple: Determine exactly what data is needed before retrieval, and then precisely fetch only that specific data.
The Precise Fetching approach drastically reduces:
- Network bandwidth consumption
- Storage I/O operations
- CPU processing overhead
- Overall query latency
How Precise Fetching Works
StarTree’s Precise Fetching changes how data is accessed from object storage through four key techniques:
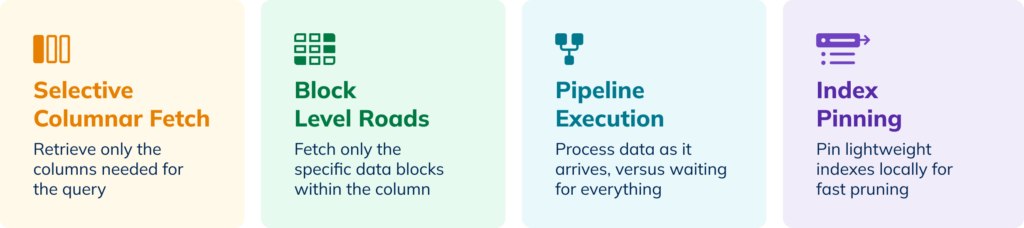
1. Selective Columnar Fetch
Unlike systems that must retrieve entire partitions (in Pinot partitions are called ‘segments’) with all columns, StarTree can selectively fetch only the columns or indexes needed for a specific query.
Example: For a query like SELECT SUM(impressions) WHERE region='rivendell', Precise Fetching will only retrieve:
- The inverted index and dictionary for the region column (not the actual column data itself, which is significantly larger)
- The forward index and dictionary for the impressions column
All other columns in the segment remain in cold storage, avoiding unnecessary data transfer.
2. Block-Level Reads
StarTree takes granularity a step further with block-level reads. Even when retrieving a specific column, traditional approaches would fetch the entire column data. Precise Fetching can:
- First evaluate filters using minimal data structures (like inverted indexes)
- Identify exactly which data blocks contain matching rows
- Retrieve only those specific blocks, rather than the entire column
This is particularly powerful for queries with high selectivity, where only a small percentage of rows match the filter conditions.
3. Pipeline Execution
Most systems fetch data sequentially, creating a bottleneck where each step must wait for the previous one to complete. StarTree decouples fetch operations from execution:
- Query planning and data fetching begin simultaneously
- I/O operations and processing are pipelined in parallel—a technique that maximizes throughput on cloud object stores like S3, which are specifically designed to handle multiple concurrent requests efficiently
- Subsequent processing stages can begin before all data is available
This smart prefetching and pipelining reduces query latency by up to 5x compared to sequential approaches.
4. Index Pinning and Pruning Optimizations
StarTree employs several techniques to minimize both the amount of data that needs to be processed and the amount that needs to be transferred:
- Metadata-based pruning: Using segment metadata (min/max values, bloom filters)—which is very small and kept in memory— to quickly skip irrelevant segments
- Selective index pinning: Keeping small, frequently used structures like bloom filters, sparse indexes and inverted indexes locally for ultra-fast access
- Star-Tree Index optimizations: Pinot’s Star-Tree Index works efficiently with tiered storage by breaking down the index into separate components—the tree structure (which is small and frequently accessed) and the forward indexes with pre-aggregated values. StarTree selectively pins just the lightweight tree nodes locally, enabling fast traversal without retrieving the entire index from cloud storage. Only the specific forward indexes containing the pre-aggregated values needed for a query are fetched as small block reads.
Learn more in the documentation on Tiered Storage
Success with Precise Fetching in Tiered Storage
Precise fetching with tiered storage has been proving its value with the following organizations:

Sovrn: Real-Time Publisher Analytics
- Transformed 24-48 hour delayed data to real-time analytics with sub-second query response times
- StarTree Cloud delivers “unbelievable query performance at a fraction of the cost,” efficiently handling 180+ million view events, 10+ million click events, and 1+ million revenue events
- Publishers can immediately analyze revenue, clicks, and page views to optimize content performance
- The tiered storage architecture provides “plenty of room to scale” as user numbers grow, allowing Sovrn to continue building products that help publishers focus on content creation
- Learn more »
DoorDash: Real-Time Risk & Fraud
- Risk and fraud teams primarily need hot data for recent fraud analysis readily available while efficiently accessing historical data from S3 when needed
- Slashed server count by 67% while maintaining sub-second query performance for Risk Platform analytics
- Despite moving historical data to cloud storage, DoorDash’s Risk teams maintained
real-time dashboard freshness with consistently fast query responses - Learn more »
Major Financial Services Company: Real-Time Observability of Financial Transactions
- 50% reduction in data storage costs
- 4x faster queries using Star-Tree Index
- Support for 100k spans in a single request for transaction tracing
- Learn more »
Learn more
Precise Fetching transforms cloud object storage into a high-performing option for analytics workloads. By fetching only the data needed instead of entire segments, StarTree helps customers cut storage costs by over 50% while maintaining query performance fast enough for interactive analytics applications and customer-facing data products.
If you’re interested in how your organization can leverage Precise Fetching in tiered storage to reduce data overhead, contact us for a demo of StarTree Cloud
