

For real-time analytics, data ingestion is the foundational architectural choice that dictates the limits of data freshness as well as query performance, and operational scalability. This blog presents a definitive technical comparison between the ingestion performance and architectures of Apache Pinot and ClickHouse, arguing that for mission-critical, real-time use cases, a stream-native design is fundamentally superior to one that mimics real-time through micro-batching.
For engineers building modern analytics systems, real-time isn’t just a buzzword — it’s a product requirement. Every clickstream, payment, and sensor event feeds into dashboards, models, and user-facing applications that depend on data being both fresh and queryable. The cost of delayed events & analytics is experienced in the form of inaccurate metrics & poor decisions thereof, subpar user experience and worse yet security and financial risks.
Two forms of latency define this experience:
- Data latency (freshness): How quickly new events become available for query after being produced.
- Query latency: How fast results are returned once queried.
Optimizing for one often hurts the other. Systems that buffer and batch data may achieve better query performance but sacrifice freshness. Systems that prioritize freshness must index, compact, and serve data continuously — a harder engineering problem.
That’s why the ingestion design of your analytical database matters.
Measuring Data Latency: Head-to-Head
We ran a simple, controlled test comparing Apache Pinot and ClickHouse, both consuming from the same Kafka topic with 1 million messages. Each system ran on identical t3.large instances.
Result:
- Apache Pinot made events queryable within milliseconds of being produced.
- ClickHouse showed visible “plateaus” in ingestion, with data available only after several seconds to minutes, depending on batch size.

This confirms a fundamental architectural difference: Pinot delivers continuous freshness, while ClickHouse depends on micro-batching.
Measuring Real-Time Upserts
We further extended the test to introduce upserts in the same Kafka stream to see how quickly and accurately do the 2 systems handle this.
- Pinot’s
COUNT(*)remained stable at 1M (true count). - ClickHouse’s
COUNT(*)kept growing — duplicates persisted in the query.

This inconsistency is rooted in the fundamental design choice of how ingestion was designed in ClickHouse as compared to Apache Pinot. Let’s take a deeper look into the 2 architectures.
The Architectural Divide: Stream-Native vs. Micro-Batch
The core difference between Apache Pinot and ClickHouse lies in their foundational ingestion philosophies. Pinot was designed from first principles for continuous event streams, while ClickHouse’s real-time capabilities are an adaptation built upon a batch-optimized storage engine. This leads to two fundamentally different approaches.
The ClickHouse Approach: Micro-Batch Ingestion
ClickHouse’s real-time ingestion mimics a stream but operates as a micro-batch process under the hood. This is a direct consequence of its MergeTree storage engine, which is optimized for fast, batch-oriented INSERTs. To avoid performance degradation from too many small writes (the “too many parts” problem), the system must buffer and batch incoming data. This creates a pattern of “eventual optimization,” where data is written quickly into a temporary state and then merged and optimized by background processes. This multi-stage pipeline introduces complexity and an inherent latency between when an event occurs and when it becomes available for query in a fully optimized and consistent state.
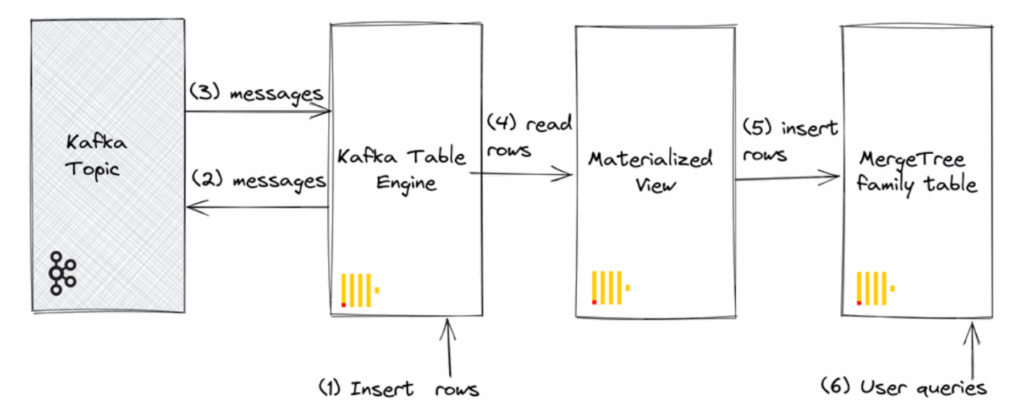
Let’s take an example of ingesting a Kafka topic into Clickhouse. This ingestion flow typically requires three components:
- A Kafka Engine Table: Acts as a transient view into a Kafka topic.
- A Materialized View: Triggers the consumption of data in batches from the Kafka Engine.
- A Final MergeTree Table: The persistent, queryable table where the batched data is ultimately stored.
This creates an inherent micro-batching behavior, even when connected to a real-time stream. This architectural choice leads to several challenges at scale:
- Higher throughput demands bigger batch sizes which sacrifices data freshness. For instance, the recommended setting of
kafka_max_block_sizeis 512k messages or more for high volume topics in Clickhouse’s Kafka table engine. That means an event generated needs to wait before it can be queried by the user. This can easily introduce 10s of seconds to minutes of delay for data to be available for query. - This design also increases the potential of data duplication during routine errors, Kafka rebalances. Although ReplacingMergeTree is designed to reconcile these duplicates – it is non deterministic and not real-time as we will see below.
The Apache Pinot Approach: Stream-Native Ingestion
Apache Pinot employs a pull-based, stream-native model designed specifically for continuous data flows. It directly consumes from streaming sources like Kafka, processing data on a row-by-row basis. The architecture is built on the principle of “upfront optimization,” where data is immediately indexed and structured for high-performance queries in memory the moment it arrives.
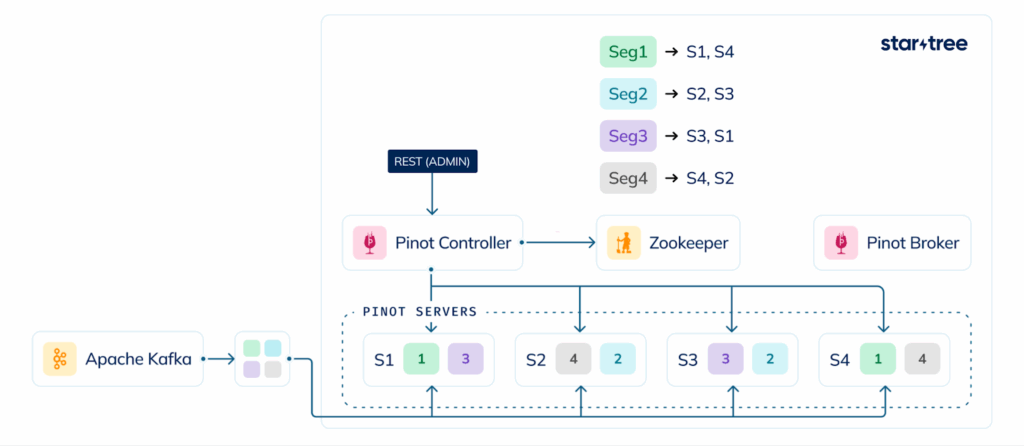
The above diagram demonstrates a sample real-time ingestion flow in Apache Pinot from Apache Kafka. Pinot controller is responsible for discovering topic partitions and assigning them to servers (including replicas). This allows each Pinot server to ingest directly from Kafka with minimal coordination. As data is pulled from Kafka, it flows directly into an in-memory CONSUMING segment and is instantly queryable. All data optimization including dictionary encoding and index creation happens on the fly as data streams in.
There are no intermediate, suboptimal states and no reliance on background processes to merge or compact data. This results in a simpler, more direct pipeline that makes data queryable within milliseconds of its creation.
Pull-Based Model with Low-Level Kafka Consumer (LLC)
Pinot does not use Kafka’s high-level Consumer Groups. Instead, it made the deliberate engineering choice to implement a Low-Level Consumer (LLC). This provides precise control and predictable performance, which are paramount for real-time OLAP workloads.
The LLC architecture provides:
- Deterministic Partition-to-Server Mapping: Each Pinot server is explicitly assigned specific Kafka partitions, eliminating the overhead and unpredictability of consumer group rebalancing.
- Zero Rebalancing Overhead: The cluster remains stable and performant even as nodes are added or removed, as there is no costly rebalancing storm to disrupt ingestion.
- Coordinated Segment Completion: Replicas can coordinate on Kafka offsets to ensure data synchronization and consistency without complex external coordination.
Why it Matters vs. ClickHouse: ClickHouse’s reliance on consumer groups means it is susceptible to “rebalancing storms” when consumers join or leave the group. This can pause consumption and introduce unpredictable latency. Pinot’s LLC avoids this entirely by using a deterministic mapping of Kafka partitions to specific Pinot servers. This ensures stable, predictable performance, even as the cluster scales.
For more details, please refer to Real-Time analytics with Kafka and Pinot blog.
Continuous Freshness with Pauseless Ingestion
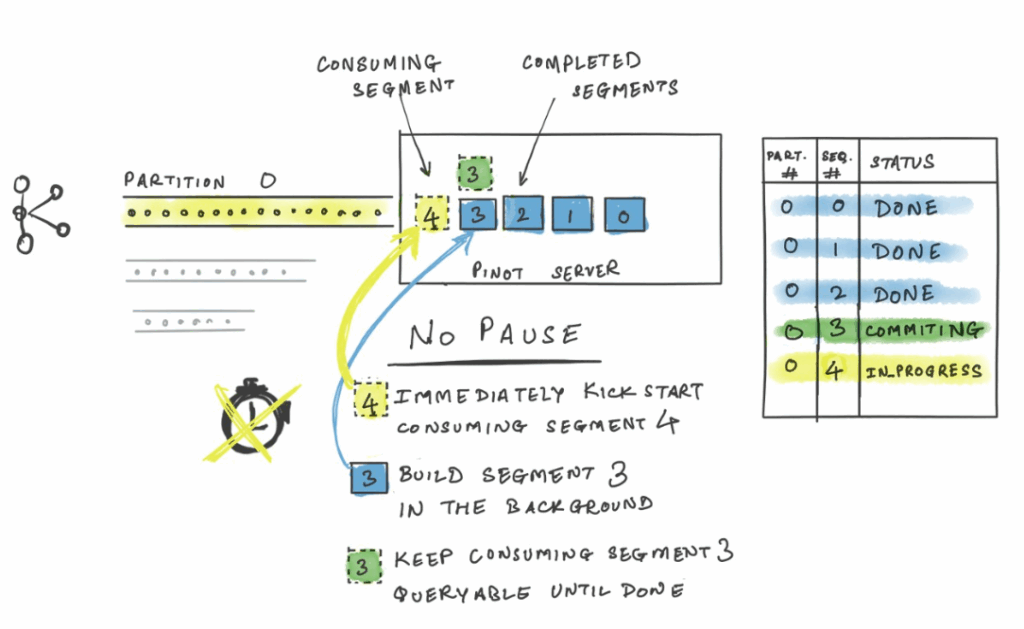
The in-memory consuming segment in Pinot is routinely sealed and persisted to disk based on certain thresholds. Historically, this sealing process introduced a brief, seconds-long pause in consumption. Pinot recently introduced Pauseless Ingestion — a feature that ensures consumption continues into a new in-memory segment with zero pause while the previous one is persisted in the background. This delivers truly continuous ingestion and guarantees millisecond-level data freshness, even under heavy load.
This architecture is designed for extreme scale, with StarTree customers leveraging Pauseless Ingestion to achieve throughputs as high as 40+ million events per second in 1 Pinot table.
Comparing Real-Time Upserts between Pinot and Clickhouse
For many mission-critical use cases, data is not purely append-only. Records must be updated to reflect the latest state. This can be in the form of financial transactions or ride sharing trips that routinely get updated. This could also be in the form of a changelog from an upstream OLTP database which gets frequently updated. Apache Pinot provides robust, native support for real-time upserts, a capability where ClickHouse has significant architectural limitations.
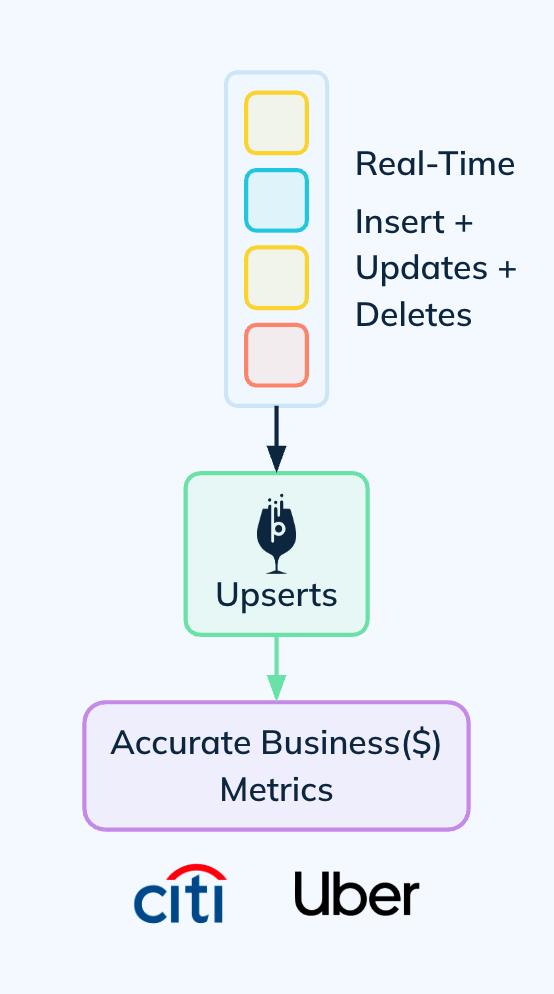
Pinot supports both full and partial upserts, allowing for efficient, column-level updates (e.g., INCREMENT a counter, APPEND to a list) based on a primary key. These operations are synchronous, meaning the updated state is immediately visible in query results. At scale, StarTree’s off-heap upserts feature allows a single server to handle several billions of primary keys without performance degradation by moving the key-to-location map out of the JVM heap.
Why it Matters vs. ClickHouse: Pinot handles updates at ingestion time. When a record with an existing primary key arrives, it is updated in place, and the change is immediately visible to all subsequent queries. ClickHouse lacks a native synchronous upsert and relies on workarounds that either delay accuracy or harm query performance:
- ReplacingMergeTree: Provides eventual consistency, as deduplication only happens during background merges. Queries may see duplicate or stale data until a merge completes.
- Mutations (
ALTER TABLE...UPDATE): These are heavyweight, asynchronous background jobs that rewrite entire data parts and are not designed for frequent, real-time updates. - Query-Time Logic: Pushes the work of finding the latest record to the read path using functions like
max(), increasing query latency and complexity.
In short, Pinot ensures data is always accurate and query-optimized on write, whereas ClickHouse’s methods require a trade-off between accuracy and read performance. In order to validate this, we did another experiment as a continuation of the above setup.

This chart shows a simple count(*) query executed against Pinot and ClickHouse. We start with the previously ingested baseline (1 million sessions) and add continuous upsert messages to the same Kafka topic. As shown, count(*) of Pinot stays constant at 1000000 entries whereas count(*) in Clickhouse keeps on increasing in spite of using ReplacingMergeTree.
If this seems a bit unexpected, note that in order for count(*) to be accurate in Clickhouse, data needs to be merged in the background to reconcile the duplicate (upsert) records. This merging is not deterministic, but kicks in based on resource availability and certain heuristics. Clickhouse does however provide a few ways of solving this problem:
- Force merge: We can tune this flag:
min_age_to_force_merge_secondswhich will force merging of any part older than this value. However, the general recommendation is not to set this to less than 30 seconds which otherwise can be very expensive and cause very high CPU spikes affecting query performance. In practice, this is set much higher in production workloads. This limits the freshness of how soon upserts can be resolved in Clickhouse. One key limitation is that once a part reaches a max age (defined bymax_bytes_to_merge_at_max_space_in_pool) – it will not be merged automatically resulting in inaccurate results. The only way around this is to use OPTIMIZE FINAL – which is basically like stop the world compaction (extremely expensive) or repartitioning the data: both these are not practical in real production workloads. - FINAL: Clickhouse provides the
FINALkeyword which can be used in queries to reconcile upserts at query time. Eg:select count(*) from user_sessions_target FINAL. This will result in scanning all the parts and coming up with an accurate count. Indeed, if we use this in our benchmark scripts, we do get the right count of 1M. However, note that usingFINALcan get very expensive. Each query has to do a lot more work to generate the right answer and the performance degrades linearly with an increase in the total amount of data hosted in Clickhouse.
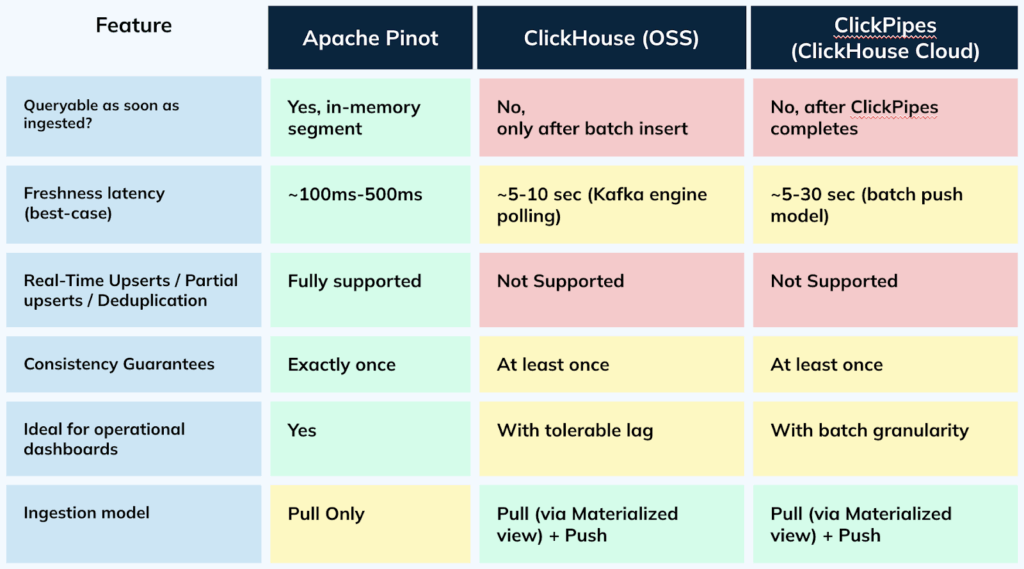
In our experiments, we could clearly see that Pinot’s design choice of reconciling upserts during ingestion is fundamentally better and more scalable than that of Clickhouse. This is summarized in the table below:

Operational Scalability and Multi-Tenancy
Architectural differences manifest as practical operational limits at scale. Anecdotally, as micro-batch systems scale, operational challenges often emerge around the number of active real-time tables, ingestion frequency, and schema complexity. Each real-time pipeline consumes significant resources, and the reliance on background merges creates bottlenecks that limit throughput and the ability to manage many tables or wide schemas efficiently. Pinot’s stream-native design, which avoids these architectural constraints, allows it to scale along these dimensions more effectively. Here’s a quick summary of the 2 systems from an operational perspective:
| Capability | Apache Pinot / StarTree | ClickHouse |
|---|---|---|
| Ingestion Latency | Very Low (Milliseconds): Events are queryable almost instantly | Moderate to High (Seconds): Recommends large message batches (500k-1M rows) to maintain performance, inherently increasing latency. |
| Consistency Guarantees | Exactly-Once: Segment generation is tied to Kafka offsets, guaranteeing no data duplication from the source. | At-Least-Once: The recommended ingestion can result in data duplication, requiring ReplacingMergeTree to handle cleanup eventually. |
| Scalability | Highly Scalable: Real-time Ingestion is natively supported can scale horizontally | Limited: Requires complex setup (multi hop) which adds an overhead and makes it difficult to scale. |
| Replication | Stream-Native Replication: Replicas consume independently from the source stream (e.g., Kafka). Synchronization is lightweight, based on stream offsets. | Internal Coordination: One replica ingests, and the system uses an internal queue in ZooKeeper/ClickHouse Keeper to distribute data parts to other replicas. In this case, Clickhouse Keeper becomes an overhead since it’s in the fast path of data ingestion. |
Conclusion: The Strategic Choice for Real-Time Ingestion
While both Apache Pinot and ClickHouse are powerful analytical databases, their ingestion architectures are fundamentally different, making them suited for different classes of problems.
ClickHouse’s real-time ingestion capabilities are an adaptation built upon a batch-optimized storage engine. This results in a micro-batch architecture that, while functional, forces a series of compromises in freshness, accuracy, and operational complexity that become increasingly problematic at scale.Apache Pinot’s stream-native, pull-based architecture is purpose-built for the demands of continuous real-time analytics. By prioritizing freshness by design, it eliminates the trade-offs inherent in systems that must buffer and eventually optimize data. It delivers millisecond-level data freshness, guaranteed exactly-once semantics, and highly scalable, synchronous upserts. For any organization building the next generation of data products where speed, scale, and accuracy are paramount, Pinot’s ingestion architecture is the superior and strategic engineering choice.
