
Data is the lifeblood of modern businesses, fueling insights, smarter decisions, and automation at massive scale. Mid-sized companies may process hundreds of gigabytes a day, while large enterprises handle hundreds of terabytes.
To ensure reliability, systems are often spread across multiple cloud availability zones (AZs). This improves resilience—but it also introduces hidden costs. Think of it like tolls: staying local is free, but crossing into a neighboring zone comes with a fee.
On AWS, for example, moving data within the same AZ costs nothing. But moving data across AZs in the same region runs about $0.02 per gigabyte once you factor in double charges for ingress and egress.
These “tolls” add up quickly. AWS has identified inter-AZ transfers as a top three cost driver[1] for data-heavy workloads. Some companies found a quarter of their total AWS bill was going to cross-AZ traffic before optimization. Broader studies[2,3,4,5] show data transfer makes up 5–20% of cloud spend, with cross-AZ accounting for over half of that total.
A big reason costs spike is how data is distributed. Modern enterprises rely on Apache Kafka as a backbone for streaming and disseminating data across applications, teams, and regions. Kafka is incredibly powerful for real-time pipelines, but when clusters span multiple AZs, every message that hops across zones racks up charges.
And it’s not just messaging systems. Data storage systems can also drive up costs. To balance load or handle spikes in demand, they may pull data from replicas in different AZs—even when a local copy exists. That means every read or write can unintentionally trigger cross-AZ transfers, multiplying the “toll charges” without teams even realizing it.
Apache Pinot is a real-time distributed OLAP datastore designed for ultra-fast analytics on high-throughput event streams and large-scale data. StarTree provides enterprise grade managed services, and commercial support for the open-source Apache Pinot.
Here’s an example configuration of a Kafka cluster, and a Pinot cluster ingesting from it. Pinot creates low-level kafka consumers on its servers, to directly ingest from a topic-partition. For a given Pinot segment, each segment replica will fetch from the corresponding Kafka partition. In this illustration, different replicas consuming from the same partition, are adding to cross AZ cost, as they aren’t AZ aware when making the connection to the brokers.
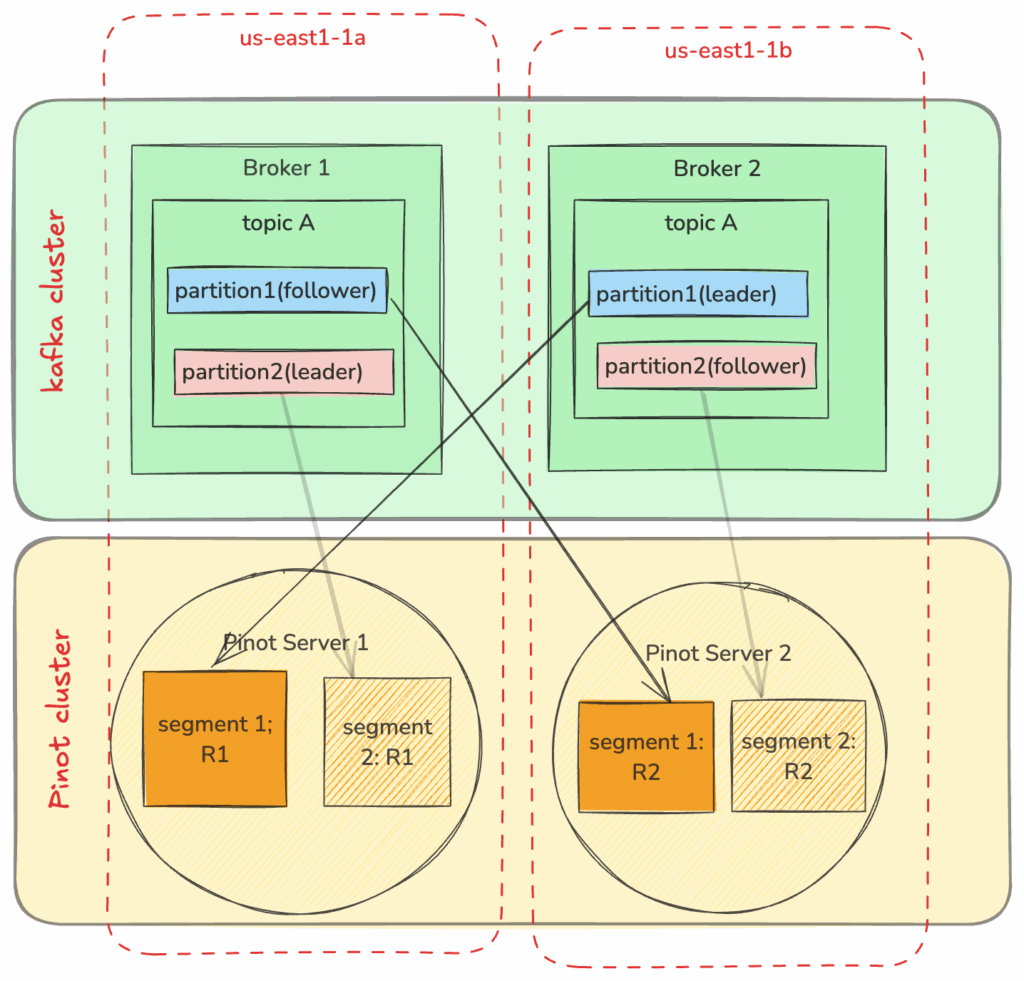
StarTree’s AZ-Aware Pinot
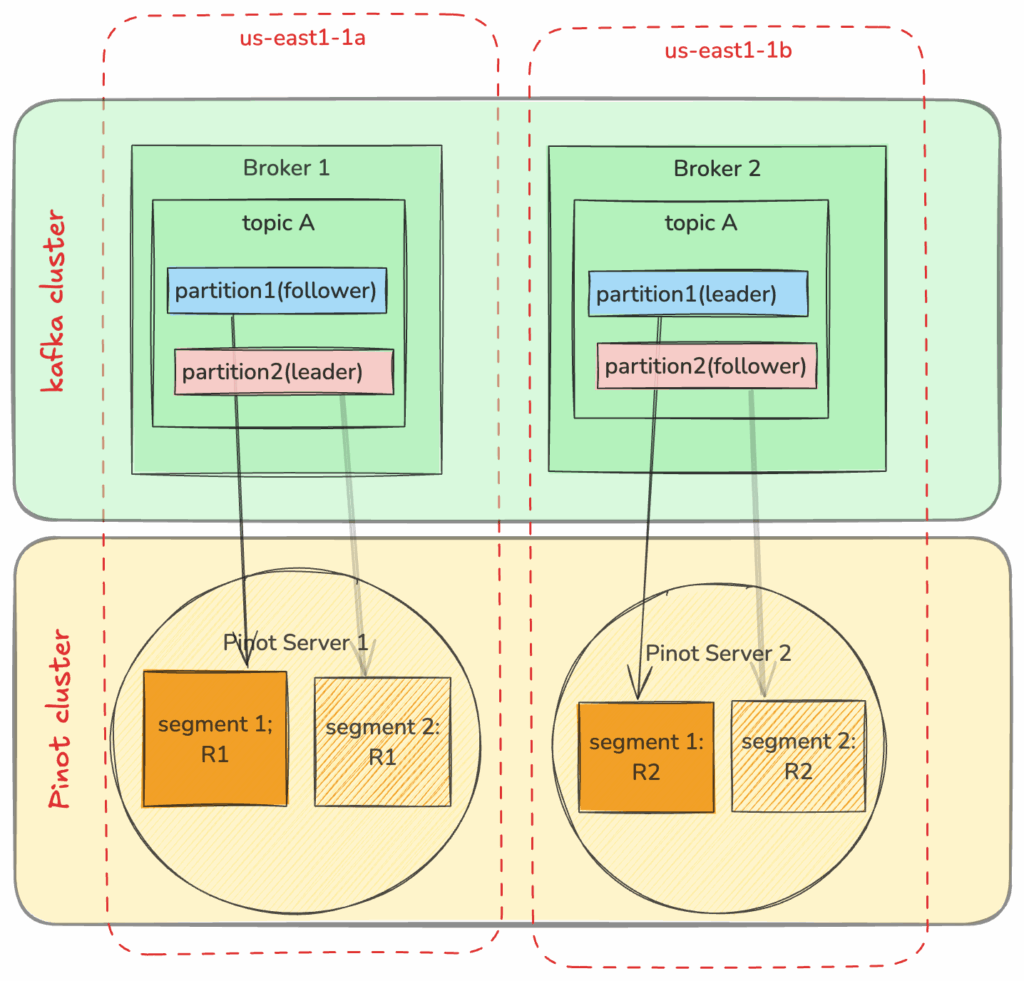
The good news: smarter architectures can minimize these costs. StarTree Cloud now supports AZ-aware ingestion for Kafka, which ensures data transfer stays local to each AZ whenever possible.
Making data ingestion AZ-aware is challenging because it must balance competing goals of low latency, high availability, consistency, and cost in distributed cloud environments. Ensuring proper data placement, failover, and consistency across AZs without creating single-AZ dependencies is non-trivial. Pinot addresses this by supporting partitioned replica-group instance assignment, enabling AZ-aware ingestion that maintains locality while still preserving the high availability and load balancing guarantees expected from a distributed system.
Think of it as keeping the conversation local. StarTree Cloud aligns with Kafka’s zone-aware design so that Pinot servers “talk” to brokers in the same AZ first. The result: faster access to data and far fewer cross-zone charges.To make this work in practice, StarTree provides a clear set of steps:
- Configure AZ-Aware Kafka Brokers – Tag brokers with their AZ so consumers can make intelligent choices.
- Configure AZ-Aware Pinot Servers – Ensure Pinot servers are also AZ-tagged for correct alignment.
- Configure AZ-Aware Table Settings – Apply zone-aware logic at the table level to ensure data stays local throughout ingestion.
- Implement AZ-Aware Instance Assignment – Store table data partitions on designated Pinot server instances with zone awareness.
AZ-Aware Kafka Broker
Many managed Kafka services already support AZ-awareness out of the box (for example, AWS MSK). If you’re running your own Kafka cluster, you’ll need to configure it manually.
Each Kafka broker must be tagged with its availability zone by setting the broker.rack property in server.properties:
broker.id=1
broker.rack=usw2-az1Repeat this for each broker, ensuring the value matches the AZ where the broker is deployed.
Next, configure consumers (such as Pinot) to use Kafka’s rack-aware replica selection:
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelectorCode language: Bash (bash)This ensures consumers preferentially fetch data from brokers in the same AZ.
AZ-Aware Pinot Server
In StarTree Cloud, Pinot servers are AZ-aware by default. Each server automatically starts up knowing which AZ it’s running in, without requiring manual tagging.
This metadata is then used during ingestion and query routing, ensuring Pinot servers align with Kafka brokers in the same zone whenever possible.
Running on AWS
CLOUD_AZ=usw2-az1
CLOUD_REGION=us-west-2AZ-Aware Table Settings
This step is to tie all together by applying AZ-awareness at the table level. This ensures that the ingestion path itself respects AZ locality.
When creating real-time tables, configure Pinot’s streamConfigs to use the same rack awareness as your Kafka brokers. StarTree Cloud automatically applies this config for all realtime Kafka tables, so you don’t have to.
"client.rack":"${CLOUD_AZ:usw2-az1}"Code language: JSON / JSON with Comments (json)This table-level setting completes the loop:
- Kafka brokers advertise their AZ.
- Pinot servers know their AZ.
- Instance assignment enforces locality.
- And tables respect it all during ingestion.
AZ-Aware Instance Assignment
Now with ingestion following AZ aware consumption, let’s look at what is needed to ensure the data distribution stays AZ aware, for all the data, beyond the segment consuming from kafka. For this we use pool-based instance assignment, which ensures partitions, segments, and replicas are placed and maintained with zone-awareness in mind.
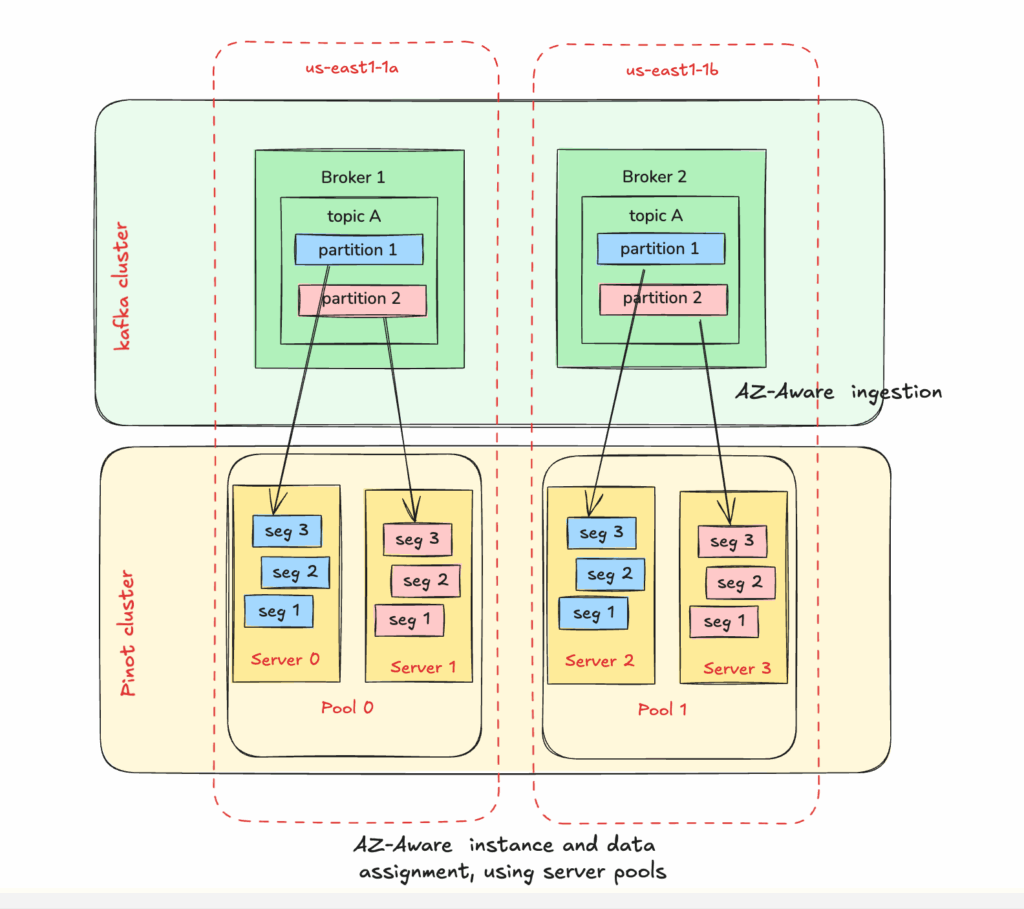
To use AZ-aware instance assignment define server pools, which assign pinot servers in different AZs with a pool tag, and assign a distinct value based on AZ, for example:
{
"listFields": {
"TAG_LIST": {
"CLOUD_AZ_POOL_REALTIME"
}
},
"mapFields": {
"pool": {
"CLOUD_AZ_POOL_REALTIME": 0
}
}
}Code language: JSON / JSON with Comments (json)In the table configuration, set the table instance by adding CLOUD_AZ_POOL_REALTIME tag and set poolBased to true to tagPoolConfig:
"instanceAssignmentConfigMap": {
"CONSUMING": {
"tagPoolConfig": {
"tag": "CLOUD_AZ_POOL_REALTIME",
"poolBased": true
},
}
}Code language: JSON / JSON with Comments (json)This ensures that all Pinot servers are divided into AZs and Pinot uses these AZ aware server pools for data placement, ensuring AZ awareness in not just ingestion, but the entire query lifecycle as well as cluster operations.
Benchmarks: The Impact of AZ-Aware Ingestion
So how much of a difference does AZ-awareness really make? In our benchmarks, the results were striking:
- Cross-AZ traffic reduction: Enabling AZ-aware ingestion reduced inter-AZ data transfers by 60–80%, depending on workload patterns.
- Cost savings: For data-heavy pipelines, this translated to 15–25% lower overall AWS bills, with the biggest impact for customers whose Kafka and Pinot clusters spanned three or more AZs.
- Consistency maintained: All of these gains came without sacrificing resiliency—data was still replicated across zones for high availability.
The Takeaway
Data movement across availability zones is one of the most overlooked—and expensive—drivers of cloud costs. What often looks like “just data flowing” can quietly become a major line item on the bill.
The solution is simple: keep data local whenever possible. By making systems like Kafka and Pinot aware of the zones they run in—and by aligning ingestion and storage with that knowledge—companies can slash unnecessary transfers without sacrificing reliability.
With StarTree Cloud, this AZ-awareness is built in. That means enterprises get the resilience they need, the performance they expect, and a cloud bill that doesn’t spiral out of control.
Reference
- [1] https://www.apmdigest.com/the-state-of-cloud-costs-2024
- [2] https://www.oracle.com/a/ocom/docs/dc/em/dao-research-aws-cost-surprises-white-paper.pdf
- [3] https://www.vantage.sh/cloud-cost-report/2025-q1
- [4] https://techbullion.com/cloud-data-transfer-costs-new-strategies-reshape-enterprise-operations
- [5] https://www.cloudcostchefs.com/docs/getting-started/understanding-costs
- [6] https://docs.pinot.apache.org/operators/operating-pinot/instance-assignment
