
Today we are both proud and excited to announce the first release of the StarTree Cloud Service, powered by Apache Pinot. In this blog, I will talk about what our cloud service will look like, how you can get access to it, and some of the exciting things we are building in our upcoming releases.

The StarTree cloud service, which is a fully managed service of Apache Pinot, is the culmination of decades of work building, operating, and perfecting Apache Pinot at LinkedIn and Uber. We have distilled all of our learnings building and operating real-time, user facing applications scaling to 100s of applications and Millions of users to build this cloud service. The primary goal of our first release is to make it easy for companies small and large to incorporate Apache Pinot and deploy user facing data applications.
Deployment Models
StarTree Cloud Service is going to be available in two primary deployment models; both will be fully managed, with the key difference being the location where the data and the infrastructure are situated. The two models will be available on all three public cloud platforms.

StarTree Managed Service (In VPC Option)
This is the deployment model available today which incorporates the best parts of a SaaS application and an on-premises deployment. The STCS will be deployed and fully managed within the customer’s public cloud infrastructure. The cluster deployment and management are fully automated and will be handled by our cloud engineering automation.
The managed service will leverage best practices of the individual public cloud providers and their API –to deploy and manage the service remotely. The StarTree automation that manages the service in the user’s public cloud will operate on the principle of least privilege, ensuring that only the minimal set of privileges needed to build and manage the service is required.
StarTree Cloud (SaaS version)
This would be the full SaaS platform that will be available by the end of this year. We will use a simple and predictable, usage based pricing to make it easy for companies small and large to adopt.
StarTree Cloud – Key Components
The cloud service we are announcing today will provide a fully managed cluster with the following key components:
- StarTree Pinot Cluster . The Data store and the Query engine for the service is a curated version of Apache Pinot. As we add more innovations around Indexing Options, Performance self-tuning techniques will become part of StarTree Pinot.
- StarTree Data Management Service . Onboard your data into the StarTree Pinot cluster using a growing number of data connectors.
- Data Query Console . A tool for ad-hoc query analysis of data that is brought into the cloud service
Onboarding Your Data With StarTree Data Management Service
The Data Management Service comes integrated with the StarTree Cloud Service. This service is designed to provide self-service capability to onboard your datasets in a simple, one-click operation.
Data Connectors
Data Connectors are a Single Click (or API) tool to ingest data from real-time or Offline data sources. The following data sources are supported in our current release:
- Real Time
- Apache Kafka
- AWS MSK
- Batch
- AWS S3
- Google Cloud Storage
- Azure Blob Storage
- One time File Upload
The connector framework will allow the user to extract individual datasets (tables) from any datasource. One of the key capabilities of Apache Pinot is its support for Lambda architecture to allow batch and real-time (streaming) data to be processed and queried. The Data connector framework will support this by combining data from a real-time and a batch data source into a single dataset.
Schema Interference
Once you point to one of the data sources of choice, the ingestion service will infer the Pinot schema for the dataset and provide a preview of what the data would look like after ingestion. The schema inference is a key value proposition that eliminates the need to understand what the data stream looks like or contains.

The ingestion service will investigate the data in the source and construct the most suitable schema. Once the schema is inferred, the ingestion service will infer the data types in your schema, identifying potential metrics and dimensions. A preview of the schema and the corresponding data will make it simpler for the users to validate the inferred schema and the data.
Data Transformations
The data ingestion service also supports inline data transformations for data scientists to add derived columns and perform any required arithmetic operations using UDFs. These transformations will be applied inline as data is ingested. Please review the following list of transformations available today.
Index Selection and Configuration
Once the data table has been defined, the service will then provide an optimal indexing option for each of the columns in your table.
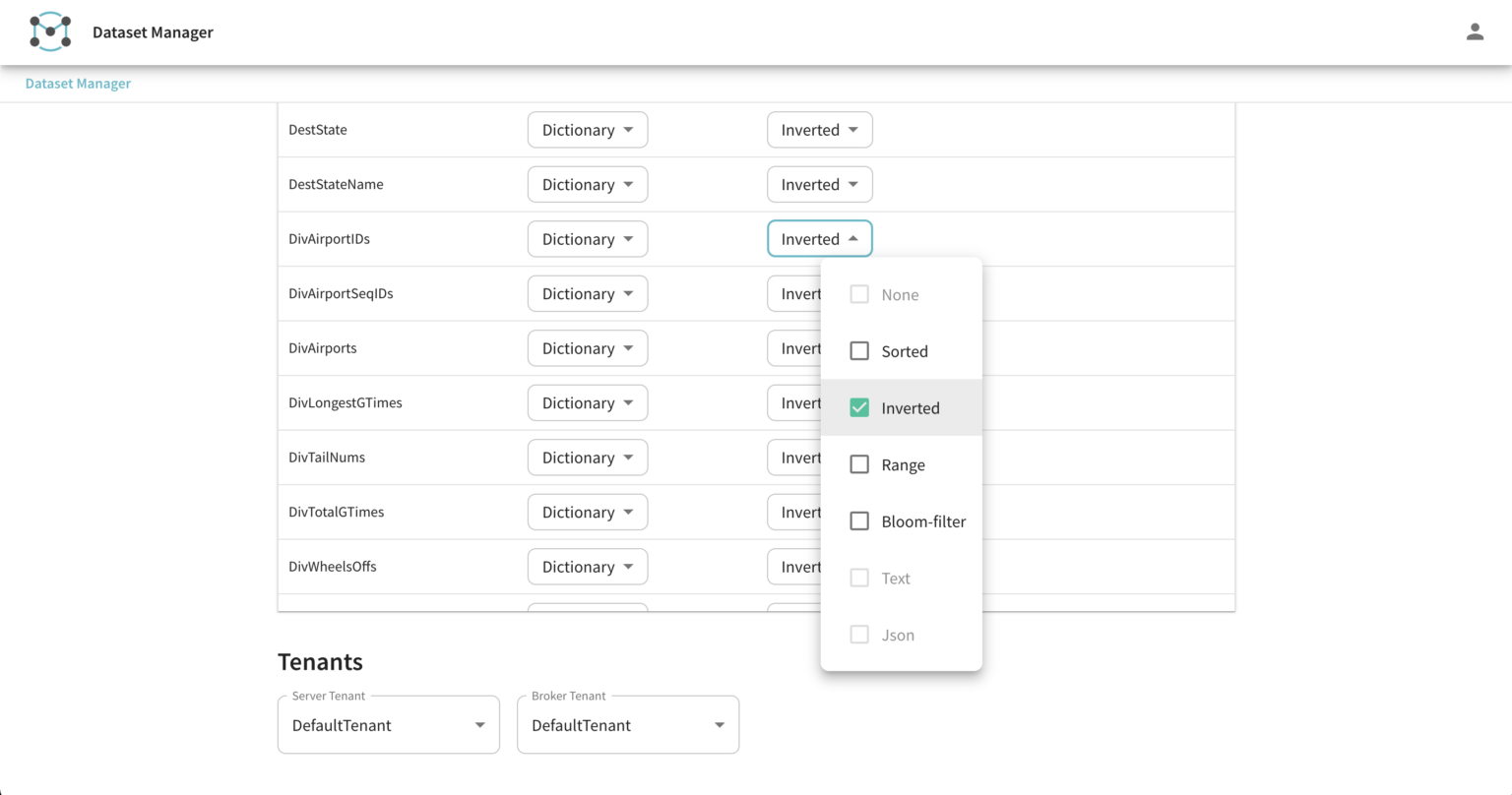
Apache Pinot natively provides a large set of data indexing options to suit various workloads. The ingestion service will pick out a selection based on the data type and best practices. We are working on an optimization to this, where the service will refine its selection of indexes based on the workload pattern. This enhancement is in the works and will be available soon. Note that one of the key value propositions of Apache Pinot is the ability to dynamically add indexes to various columns based on your workload patterns and query performance. This capability is available with our Cloud Service. In the future, we plan to automate this based on the workload.
Data Life Cycle
The data ingestion service also allows users to manage the lifecycle of data coming into the cloud service. Data scientists and developers can determine archival policies for their data sources and then automate them.
Summary
StarTree Cloud Service is a fully managed analytics platform based on Apache Pinot. The cloud service is built by the original creators and operators of Apache Pinot from Uber and LinkedIn. The cloud service is built to ensure organizations can focus on building real-time, site-facing applications to bring immediate insights to their end-users. The goal of our initial release is to make it easy for companies to evaluate Apache Pinot. This will be a full-featured cloud service that you can use to adopt Pinot and the StarTree platform. Please click the link below to get started.
More Resources:
- Join the Pinot slack channel: https://communityinviter.com/apps/apache-pinot/apache-pinot
- See our upcoming events: https://www.meetup.com/apache-pinot
- Follow StarTree on Twitter: https://twitter.com/startreedata
- Subscribe to our YouTube channel: https://www.youtube.com/startreedata
