
Apache Pinot is an open source, distributed, OLAP datastore used for performing millisecond granularity analytical queries on real-time as well as offline data sources. It is highly scalable by design and can easily support site-facing analytics such as LinkedIn’s “Who Viewed My Profile” or Uber’s “Restaurant Manager” in a reliable manner. A typical production Pinot cluster can handle millions of Kafka events, terabytes of Hadoop data while serving 100K+ queries/second with strict low latency SLA.
In this article, we talk about how users can build critical site-facing analytical applications requiring high throughput and strict p99th query latency SLA using Apache Pinot.
We will go through the challenges of serving concurrent, low latency SLA queries in Pinot’s distributed environment. Next, we elaborate on the internals of segment assignment and routing strategies and how we can configure them to ensure optimum query performance. We will also talk about data partitioning strategy and how it can further optimize query throughput and latency.
Pinot Query Execution Overview
Pinot organizes the incoming data into smaller chunks called “segments” and distributes it across the Pinot Servers. When a user/client application tries to query this data, all these servers process it in parallel as shown in the diagram below:
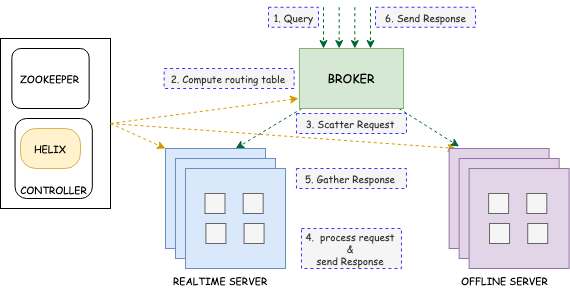
The Pinot Broker receives the user query and scatters it to the corresponding set of Pinot Servers hosting the segments. In turn, each server will locally execute the query and send the response back to the Broker. The broker then consolidates all the individual responses and sends them back to the client. You can find more information about this here.
Challenge of maintaining p99th query latency SLA
Let’s take LinkedIn’s Feed ranking use case which leverages Pinot for curating the home page feed recommendations to its 700+ million users.
For a given feed item, we want to know how many times has a given user seen it to decide whether it should be displayed. This can be done using the following query:
SELECT sum(count) from T WHERE memberId = X AND item in (list of 500-1500 items) AND time >= (now - 14 days) GROUP BY action, item, position, timeCode language: JavaScript (javascript)This will run for every single active user visiting the LinkedIn home page, translating to multiple 1000s of OLAP queries to Pinot. For a good user experience, it is critical that the p99th latency is under 100ms. This is non-trivial to achieve since traditional RDBMS/OLTP stores don’t scale for such analytical workloads. Even though Apache Pinot was built for such use cases, we need to tune it correctly to ensure p99th SLA.
In distributed systems, adding more machines typically improves overall performance. However, the devil is always in the details. In the case of Apache Pinot, although adding more servers will help in improving average throughput and latency, the p99th query latency might go up. This is because, if the Broker routes the request to a lot of servers, the probability of hitting a slow server is high. Some servers might intermittently experience high memory or CPU overhead, increasing local query response time and thus causing higher tail end latencies.
Tuning Pinot for predictable performance
Thankfully, Apache Pinot provides powerful knobs to tune the query performance and guarantee SLA for such critical use cases. The high-level principles for achieving this are:
- Reduce the number of servers required to execute a query
- Reduce the number of segments required to execute a query
Reducing the number of servers per query
By default, a Pinot Broker will send the query request to all the available servers hosting the segments. As mentioned before, if the table footprint is large (i.e. mapped to a lot of servers), it will deteriorate the p99th query latency because of the probability of hitting a slow server. We can reduce this query span by limiting the number of servers responsible for storing data for a given table. This is done using the concept of ‘Replica Groups’ .
A Replica group is a subset of servers that contain a complete set of segments for a given table. This can be configured in the table index config wherein the table owner can specify:
- Number of replicas: for a segment belonging to this table
- Number of Instances per replica group: specifies the number of servers that contain a complete copy of all segments for this table.
For example, we can configure something like this:

In this case, we’re configuring 3 replica groups with 4 instances each. In other words, each group of 4 servers hosts a complete copy of the table segments. When a query is issued, the Pinot Broker will look at the table indexing config and identify any one replica group to route the query to as shown below:
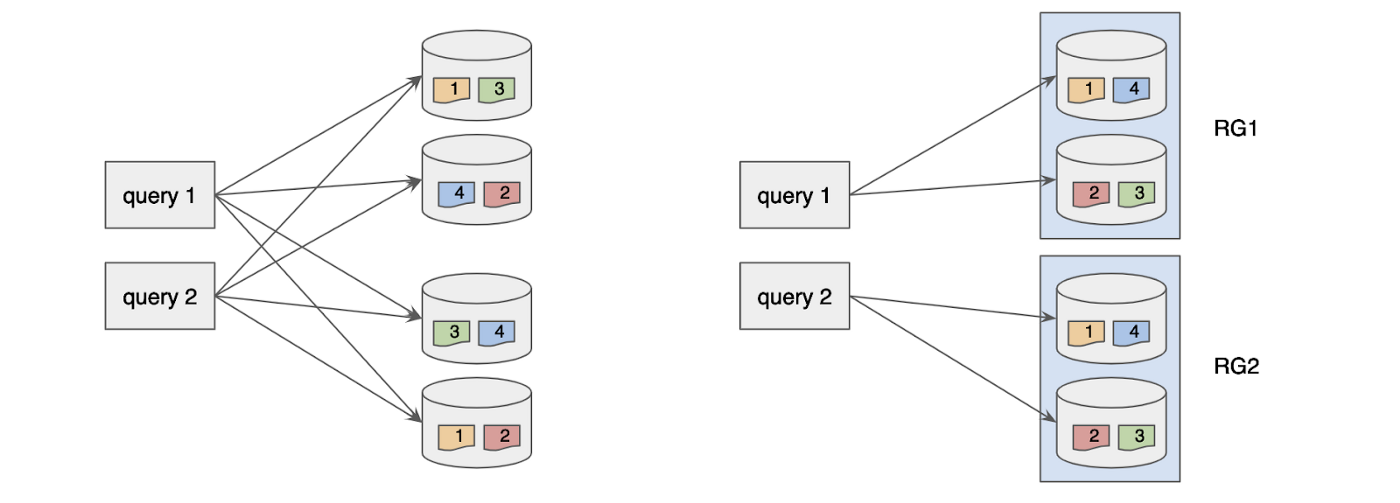
This helps in reducing the number of servers processing a given query and hence improves the p99th query latency. For more information on replica groups, please refer to this doc.
Reducing the number of Segments scanned
Limiting the number of servers for a given table is a good start. We can further reduce the query span by limiting the number of segments processed for a given query. This is accomplished by partitioning the incoming data on a particular dimension which is heavily utilized in filter predicates.
For instance, in the use case discussed above, we can partition the data on ‘memberId’ (referring to a unique identifier for a LinkedIn member), by adding this to the table config:

Here, we’ve configured 4 partitions on the ‘memberId’ dimension. When a query specifying a particular memberID is issued, the Pinot Broker can map it to a particular partition and identify a subset of segments that need to be queried. The request is only sent to the corresponding servers hosting this subset of segments. This reduces both the number of servers as well as the number of segments processed per server, thus reducing overhead by 75% and making the query latency more predictable. For understanding how partitioning works in more detail, please refer to this doc.
After these optimizations are applied, the p99th query latency becomes much more predictable as shown in the following benchmark:
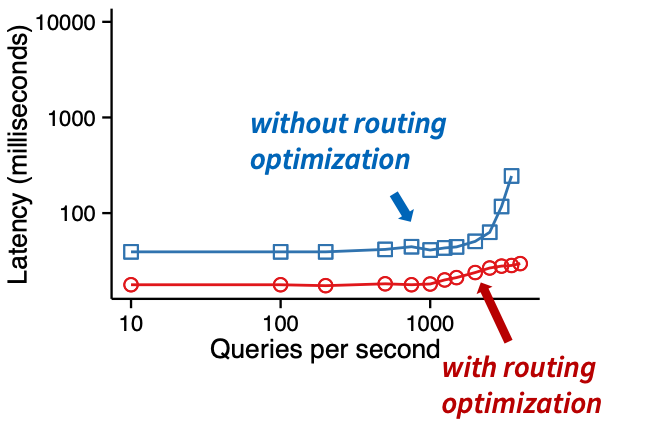
As of today, LinkedIn can serve this use case reliably with a QPS of multiple 1000s of queries and a p99th query latency of around 80–100ms which is quite impressive.
Conclusion
Apache Pinot is being used for critical analytical applications across a variety of industry domains, primarily because of its ability to serve high throughput, low latency queries. In this blog, we saw that by default, Pinot was engineered to easily scale out to meet the organic growth. However, oftentimes we need to tune the partitioning and segment assignment strategy and reduce the segment footprint for predictable performance.
Learning more
If you’re interested in learning more about Pinot, become a member of our open source community by joining our Slack channel and subscribing to our mailing list.
We’re excited to see how developers and companies are using Apache Pinot to build highly-scalable analytical queries on real-time event data. Feel free to ping us on Twitter or Slack with your stories and feedback.
- Slack: https://communityinviter.com/apps/apache-pinot/apache-pinot
- Meetup: https://www.meetup.com/apache-pinot/
- Twitter: @apachepinot https://twitter.com/ApachePinot
- Apache mailing list: [email protected]
Finally, here is a list of resources that you might find useful as you start your journey with Apache Pinot.
- Docs: http://docs.apache.pinot.org
- Download: http://pinot.apache.org/download
- Getting Started: https://docs.pinot.apache.org/getting-started
- Subscribe to our YouTube channel: https://www.youtube.com/startreedata